Spark安装
spark-2.1.0-bin-hadoop2.7.tgz
scala-2.12.1.tgz
jdk-8u121-linux-x64.tar.gz
export JAVA_HOME=/home/python/Downloads/jdk1.8.0_121
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export SPARK_HOME=/home/python/Downloads/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export SCALA_HOME=/home/python/Downloads/scala-2.12.1
export PATH=$PATH:$SCALA_HOME/bin
如果想要环境变量永久生效可以修改下面两个文件中的任何一个:
1 /etc/profile
2 .bash_profile
其中,/etc/profile是全局的环境变量,对所有用户生效,而.bash_profile只对当前用户启作用。
export JAVA_HOME=/home/share/jdk1.8.0_121
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export SPARK_HOME=/home/share/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export SCALA_HOME=/home/elchen/Downloads/scala-2.10.6
export PATH=$PATH:$SCALA_HOME/bin
export PATH=$PATH:/usr/local/mongodb/bin/
export LD_LIBRARY_PATH=/usr/lib:/usr/lib64:/lib:/lib64:/usr/local/lib:/usr/local/lib64:$LD_LIBRARY_PATH
export ES_HOME=/usr/local/elasticsearch-5.0.0
PySpark pip installable
If you are building Spark for use in a Python environment and you wish to pip install it, you will first need to build the Spark JARs as described above. Then you can construct an sdist package suitable for setup.py and pip installable package.
进入pyspark目录下:
cd python; python setup.py sdist
Note: Due to packaging requirements you can not directly pip install from the Python directory, rather you must first build the sdist package as described above.
copy D:\spark-2.0.0-bin-hadoop2.7\python\pyspark to [Your-Python-Home]\Lib\site-packages
spark部署standalone集群
5:配置spark
复制配置文件 cp spark-env.sh.template spark-env.sh
在spark-env.sh最后添加下面
export SCALA_HOME=/home/elchen/Downloads/scala-2.10.6 export SPARK_MASTER_IP=192.168.1.100 export SPARK_WORKER_MEMORY=2G export JAVA_HOME=/home/share/jdk1.8.0_121
6:启动
[jifeng@jifeng01 sbin]$ cd ..
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ sbin/start-master.sh
error:
└─(root@host-192-168-1-20)$ ./sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /home/share/spark-2.1.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-host-192-168-1-20.out localhost: Permission denied (publickey)
~/.ssh/id_rsa.pub copyto vi ~/.ssh/authorized_keys
└─(root@host-192-168-1-20)$ tail -f /home/share/spark-2.1.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-host-192-168-1-20.out
17/05/28 20:31:12 INFO Worker: Starting Spark worker 192.168.1.20:42530 with 16 cores, 2.0 GB RAM
17/05/28 20:31:12 INFO Worker: Running Spark version 2.1.0
17/05/28 20:31:12 INFO Worker: Spark home: /home/share/spark-2.1.0-bin-hadoop2.7
17/05/28 20:31:12 WARN Utils: Service 'WorkerUI' could not bind on port 8081. Attempting port 8082.
17/05/28 20:31:12 WARN Utils: Service 'WorkerUI' could not bind on port 8082. Attempting port 8083.
17/05/28 20:31:12 INFO Utils: Successfully started service 'WorkerUI' on port 8083.
17/05/28 20:31:12 INFO WorkerWebUI: Bound WorkerWebUI to 0.0.0.0, and started at http://192.168.1.20:8083
17/05/28 20:31:12 INFO Worker: Connecting to master host-192-168-1-20.openstacklocal:7077...
17/05/28 20:31:12 INFO TransportClientFactory: Successfully created connection to host-192-168-1-20.openstacklocal/192.168.1.20:7077 after 33 ms (0 ms spent in bootstraps)
17/05/28 20:31:12 INFO Worker: Successfully registered with master spark://host-192-168-1-20.openstacklocal:7077
通过 http://192.168.1.100:8083/看到对应界面
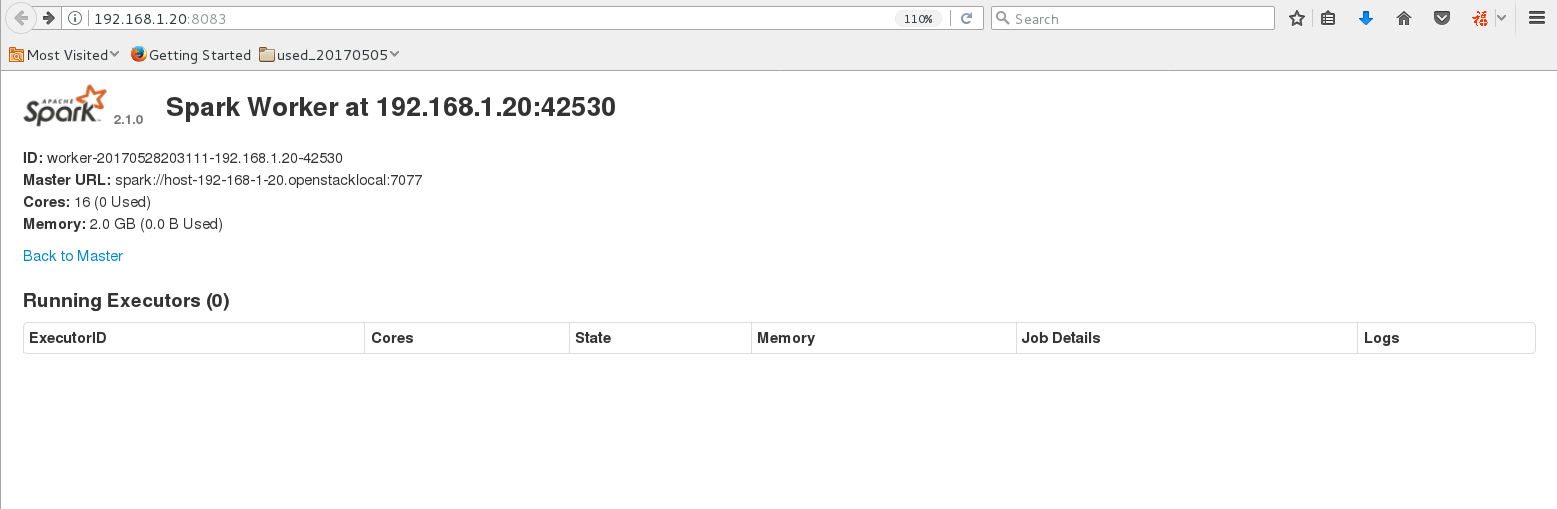 7:启动worker
7:启动worker
sbin/start-slaves.sh spark://host-192-168-1-20.openstacklocal:7077
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ sbin/start-slaves.sh park://jifeng01:7077 localhost: Warning: Permanently added 'localhost' (RSA) to the list of known hosts. localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/jifeng/hadoop/spark-1.2.0-bin-hadoop1/sbin/../logs/spark-jifeng-org.apache.spark.deploy.worker.Worker-1-jifeng01.sohudo.com.out [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ sbin/start-slaves.sh park://jifeng01.sohudo.com:7077 localhost: org.apache.spark.deploy.worker.Worker running as process 10273. Stop it first. [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$
看界面的变化
http://host-192-168-1-20.openstacklocal:8080/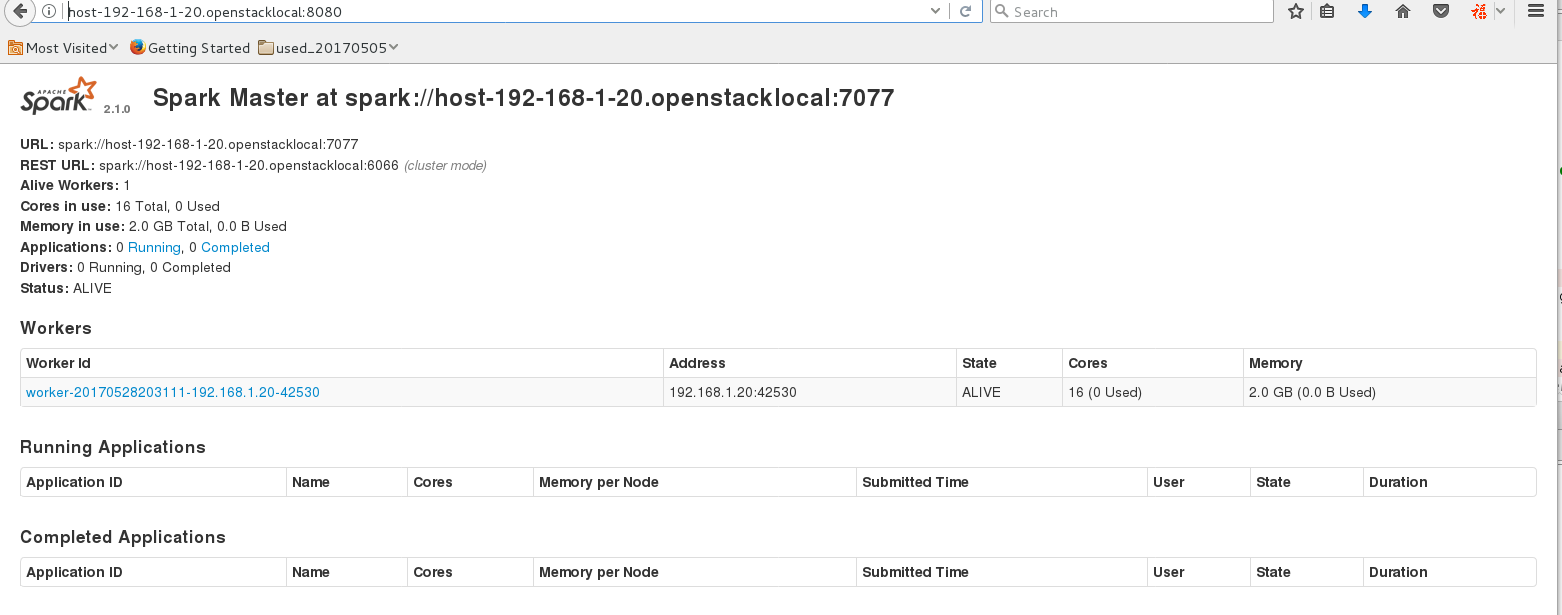
8:测试
进入交互模式
└─(root@host-192-168-1-20)$ master=spark://host-192-168-1-20.openstacklocal:7077 bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/05/28 21:09:03 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/05/28 21:09:10 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/05/28 21:09:10 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
17/05/28 21:09:11 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.1.20:4040
Spark context available as 'sc' (master = local[*], app id = local-1495976944035).
Spark session available as 'spark'.
Welcome to____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.1.0 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_121) Type in expressions to have them evaluated. Type :help for more information. scala>
测试
输入命令:
val file=sc.textFile("hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt")
val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
count.collect()
看到控制台有如下结果:res0: Array[(String, Int)] = Array((hadoop,1), (hello,1))
同时也可以将结果保存到HDFS上
scala>count.saveAsTextFile("hdfs://jifeng01.sohudo.com:9000/user/jifeng/out/test1.txt")
9:停止
- [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ ./sbin/stop-master.sh
- stopping org.apache.spark.deploy.master.Master
http://blog.csdn.net/wind520/article/details/43458925
Test Example:
# !/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import print_function
from pyspark.sql import SparkSession
# $example on:schema_merging$
from pyspark.sql import Row
import re
from datetime import datetime
import pyspark.sql.functions as func
def myFunc(s):
# s = '[2017-03-16 12:30:28,383](INFO)record : user: hxzb:hxzb201703@172.106.46.78:8888, timestamp: 1489638628341, ip: hxzb:hxzb201703@172.106.46.78:8888, channel_code: 9010'
user = re.search("user: (.*?),", s).group(1)
time_field = re.search("timestamp: (.*?),", s).group(1)
timestamp = datetime.fromtimestamp(float(time_field))
ip = re.search("ip: (.*?),", s).group(1)
channel_code = re.search("channel_code: (\d+)", s).group(1)
return user, timestamp, channel_code, ip
def parquet_schema_merging_example(spark):
lines = spark.sparkContext
# parts = lines.textFile("file.txt").map(myFunc)
parts = lines.textFile("/home/share/PROXY/proxy_0411/merge.log").filter(lambda line: "user" in line).map(myFunc)
# parts.collect()
logTable = parts.map(lambda p: Row(user=p[0], timestamp=p[1],channel_code=int(p[2]),ip=p[3]))
# Infer the schema, and register the DataFrame as a table.
schemaLog = spark.createDataFrame(logTable)
schemaLog.createOrReplaceTempView("Log")
# SQL can be run over DataFrames that have been registered as a table.
spark.sql("SELECT * FROM Log").show(3,truncate=40)
# The results of SQL queries are Dataframe objects.
# rdd returns the content as an :class:`pyspark.RDD` of :class:`Row`.
# teenNames = teenagers.rdd.map(lambda p: "user: " + p.user).collect()
# for name in teenNames:
# print(name)
dataCache = schemaLog.filter(schemaLog.timestamp >= '2017-04-10 17:00:00').select("user", func.date_format("timestamp", "yyyy/MM/dd HH").alias("average_hour"), "ip", "channel_code")
dataCache.cache()
spark.sql("SELECT * FROM Log").show(3, truncate=40)
# 统计每个账户、每小时、渠道、被调用次数
print("---统计每个账户、每小时、渠道被调用次数---")
dataCache.groupBy("user","average_hour","channel_code").agg(func.count("channel_code")).sort(dataCache.user.desc(),dataCache.average_hour.desc(),dataCache.channel_code.desc()).show(n=1000,truncate=40)
# 统计 每个账户、每小时、切换ip次数
print("---统计 每个账户、每小时、切换ip次数---")
dataCache.groupBy("user","average_hour").agg(func.approx_count_distinct("ip").alias('distinct_ip')).sort(dataCache.user.desc(),dataCache.average_hour.desc()).show(truncate=40)
#dataCache.groupBy("user","average_hour").agg(func.approx_count_distinct(dataCache.ip).alias('distinct_ip')).orderBy(dataCache.user.desc(),dataCache.average_hour.desc()).filter("distinct_ip!=1").show(n=2000,truncate=40)
# 总计统计 每个渠道、每个账户下,调用次数
print("---总计统计 每个渠道、每小时、每个账户、切换IP次数---")
dataCache.groupBy("channel_code","average_hour", "user").agg(func.approx_count_distinct("ip").alias('distinct_ip')).sort(dataCache.channel_code.desc(), dataCache.average_hour.desc()).filter("distinct_ip!=1").show(n=20000, truncate=40)
dataCache.groupBy("channel_code", "average_hour", "user").agg(
func.approx_count_distinct("ip").alias('distinct_ip')).orderBy(["channel_code", "average_hour","distinct_ip","user"], ascending=[1, 1]).filter(
"distinct_ip!=1").show(n=20000, truncate=40)
#dataCache.groupBy("channel_code", "user").agg(func.approx_count_distinct("ip").alias('distinct_ip')).filter("distinct_ip!=1").show(n=20000,truncate=40)
#>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
# >> > df.orderBy(desc("age"), "name").collect()
# [Row(age=5, name=u'Bob'), Row(age=2, name=u'Alice')]
# >> > df.orderBy(["age", "name"], ascending=[0, 1]).collect()
# [Row(age=5, name=u'Bob'), Row(age=2, name=u'Alice')]
#---------------------------------------------------------
# 统计 每个渠道、每个账户下, 每小时调用次数
print("---统计 每个渠道、每个账户下, 每小时调用次数---")
dataCache.groupBy("channel_code", "average_hour", "user").agg(func.count("ip")).sort(dataCache.channel_code.desc(), dataCache.average_hour.desc()).show(n=10000,truncate=40)
#dataCache.groupBy("channel_code", "user", "average_hour").agg(func.count("ip")).sort(dataCache.channel_code.desc(), dataCache.user.desc()).show(truncate=40)
# 统计 每个渠道、每个账户下, 每小时调用次数
print("---统计 每个渠道, 每小时、每个账户下调用次数---")
dataCache.groupBy("channel_code", "average_hour", "user").agg(func.count("ip")).sort(dataCache.channel_code.desc(),dataCache.average_hour.desc()).show(n=10000, truncate=40)
# dataCache.groupBy("channel_code", "user", "average_hour").agg(func.count("ip")).sort(dataCache.channel_code.desc(), dataCache.user.desc()).show(truncate=40)
# 统计 每个账户、每小时、切换ip次数
print("---统计 每个账户、每小时、每个渠道、调用次数---")
dataCache.groupBy("user", "average_hour", "channel_code").agg(func.count("channel_code")).sort(
dataCache.user.desc(), dataCache.average_hour.desc()).show(truncate=40)
# dataCache.groupBy("user","average_hour").agg(func.approx_count_distinct(dataCache.ip).alias('distinct_ip')).orderBy(dataCache.user.desc(),dataCache.average_hour.desc()).filter("distinct_ip!=1").show(n=2000,truncate=40)
print("---统计 每个渠道、调用次数---")
dataCache.groupBy("channel_code").agg(func.count("channel_code")).orderBy(["count(channel_code)"],ascending=[0]).show(n=200, truncate=40)
print("---统计 每个账户、调用次数---")
ASCENDING__SHOW = dataCache.groupBy("user").agg(func.count("user")).orderBy(["count(user)"], ascending=[0]).show(n=200,
truncate=40)
pass
if __name__ == "__main__":
spark = SparkSession.builder.appName("Python Spark SQL data source example").getOrCreate()
parquet_schema_merging_example(spark)
executor:
└─(root@host-192-168-1-20)$ spark-submit --master spark://host-192-168-1-20.openstacklocal:7077 --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0 test_spark.py
Ivy Default Cache set to: /root/.ivy2/cache
The jars for the packages stored in: /root/.ivy2/jars
:: loading settings :: url = jar:file:/home/share/spark-2.1.0-bin-hadoop2.7/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
org.apache.spark#spark-streaming-kafka_2.10 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent;1.0
confs: [default]
found org.apache.spark#spark-streaming-kafka_2.10;1.6.0 in central
found org.apache.kafka#kafka_2.10;0.8.2.1 in central
found com.yammer.metrics#metrics-core;2.2.0 in central
found org.slf4j#slf4j-api;1.7.10 in central
found org.apache.kafka#kafka-clients;0.8.2.1 in central
found net.jpountz.lz4#lz4;1.3.0 in central
found org.xerial.snappy#snappy-java;1.1.2 in central
found com.101tec#zkclient;0.3 in central
found log4j#log4j;1.2.17 in central
found org.spark-project.spark#unused;1.0.0 in central
downloading https://repo1.maven.org/maven2/org/apache/spark/spark-streaming-kafka_2.10/1.6.0/spark-streaming-kafka_2.10-1.6.0.jar ...
[SUCCESSFUL ] org.apache.spark#spark-streaming-kafka_2.10;1.6.0!spark-streaming-kafka_2.10.jar (861ms)
downloading https://repo1.maven.org/maven2/org/apache/kafka/kafka_2.10/0.8.2.1/kafka_2.10-0.8.2.1.jar ...