Python 使用 Redis
参考文档:
http://redis.cn/clients.html#python
https://github.com/andymccurdy/redis-py
安装Redis
sudo pip install redis
简单的redis操作
字符串string操作
In [1]: import redis
In [2]: r = redis.StrictRedis(host='localhost', port=6379, db=0, password='foobared')
In [3]: r.set('foo', 'bar')
Out[3]: True
In [4]: r.get('foo')
Out[4]: 'bar'
In [5]: r['foo']
Out[5]: 'bar'
In [6]: r.delete('foo')
Out[6]: 1
In [7]: r.get('foo')
In [8]:r.sadd('setmy','a')
Out[8]: 1
In [10]: r.s('setmy')
r.sadd r.setex
r.save r.setnx
r.scan r.setrange
r.scan_iter r.shutdown
r.scard r.sinter
r.script_exists r.sinterstore
r.script_flush r.sismember
r.script_kill r.slaveof
r.script_load r.slowlog_get
r.sdiff r.slowlog_len
r.sdiffstore r.slowlog_reset
r.sentinel r.smembers
r.sentinel_get_master_addr_by_name r.smove
r.sentinel_master r.sort
r.sentinel_masters r.spop
r.sentinel_monitor r.srandmember
r.sentinel_remove r.srem
r.sentinel_sentinels r.sscan
r.sentinel_set r.sscan_iter
r.sentinel_slaves r.strlen
r.set r.substr
r.set_response_callback r.sunion
r.setbit r.sunionstore
In [10]: r.smembers('setmy')
Out[10]: {'a'}
pipeline操作
管道(pipeline)是redis在提供单个请求中缓冲多条服务器命令的基类的子类。它通过减少服务器-客户端之间反复的TCP数据库包,从而大大提高了执行批量命令的功能。
>>> p = r.pipeline() --创建一个管道
>>> p.set('hello','redis')
>>> p.sadd('faz','baz')
>>> p.incr('num')
>>> p.execute()
[True, 1, 1]
>>> r.get('hello')
'redis'
管道的命令可以写在一起,如:
>>> p.set('hello','redis').sadd('faz','baz').incr('num').execute()
1
默认的情况下,管道里执行的命令可以保证执行的原子性,执行pipe = r.pipeline(transaction=False)可以禁用这一特性。
字符串应用场景 – 页面点击数
假定我们对一系列页面需要记录点击次数。例如论坛的每个帖子都要记录点击次数,而点击次数比回帖的次数的多得多。如果使用关系数据库来存储点击,可能存在大量的行级锁争用。所以,点击数的增加使用redis的INCR命令最好不过了。
当redis服务器启动时,可以从关系数据库读入点击数的初始值(1237这个页面被访问了34634次)
>>> r.set("visit:1237:totals",34634)
True
每当有一个页面点击,则使用INCR增加点击数即可。
>>> r.incr("visit:1237:totals")
34635
>>> r.incr("visit:1237:totals")
34636
页面载入的时候则可直接获取这个值
>>> r.get ("visit:1237:totals")
'34636'
使用hash类型保存多样化对象
应用场景
比如我们要存储一个用户信息对象数据, 用户的姓名、年龄、生日等,修改某一项的值。Redis的Hash结构可以使像在数据库中Update一个属性一样只修改某一项属性值。
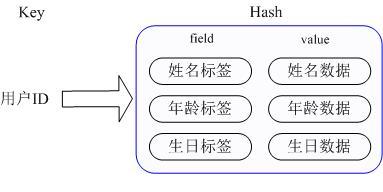
Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:
>>> r.hset('users:jdoe', 'name', "John Doe")
1L
>>> r.hset('users:jdoe', 'age', 25)
1L
>>> r.hset('users:jdoe', 'birthday', '19910101')
1L
>>> r.hgetall('users:jdoe')
{'age': '26', 'birthday': '19910101', 'name': 'John Doe'}
>>> r.hkeys('users:jdoe')
['name', 'age', 'birthday']
>>> r.hincrby('users:jdoe', 'age', 1)
26L
>>> r.hgetall('users:jdoe')
>>> {'age': '26', 'birthday': '19910101', 'name': 'John Doe'}
Set集合应用场景 – 社交圈子数据
在社交网站中,每一个圈子(circle)都有自己的用户群。通过圈子可以找到有共同特征(比如某一体育活动、游戏、电影等爱好者)的人。当一个用户加入一个或几个圈子后,系统可以向这个用户推荐圈子中的人。 我们定义这样两个圈子,并加入一些圈子成员。
>>> r.sadd('circle:game:lol','user:debugo')
1
>>> r.sadd('circle:game:lol','user:leo')
1
>>> r.sadd('circle:game:lol','user:Guo')
1
>>> r.sadd('circle:soccer:InterMilan','user:Guo')
1
>>> r.sadd('circle:soccer:InterMilan','user:Levis')
1
>>> r.sadd('circle:soccer:InterMilan','user:leo')
1
获得某一圈子的成员
>>> r.smembers('circle:game:lol')
set(['user:Guo', 'user:debugo', 'user:leo'])
可以使用集合运算来得到几个圈子的共同成员:
>>> r.sinter('circle:game:lol', 'circle:soccer:InterMilan')
set(['user:Guo', 'user:leo'])
>>> r.sunion('circle:game:lol', 'circle:soccer:InterMilan')
set(['user:Levis', 'user:Guo', 'user:debugo', 'user:leo'])
推荐游戏soccer:InterMilan:
>>> r.sdiff('circle:game:lol','circle:soccer:InterMilan')
>>> {'user:debugo'}