MongoDB Map-Reduce(MR)
Google在2003年到2004年公布了关于GFS、MapReduce和BigTable三篇技术论文,这也成为后来云计算发展的重要基石,
谷歌技术有"三宝",GFS(分布式文件系统)、MapReduce编程模型(Map映射和Reduce归约)和BigTable(分布式数据存储系统)!
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果规约(REDUCE)成最终结果。
Google 2014年 I/O大会:Google已经停用MapReduce,开发并发布了一个新的超大规模云分析系统Cloud Dataflow。
MapReduce 命令
以下是MapReduce的基本语法:
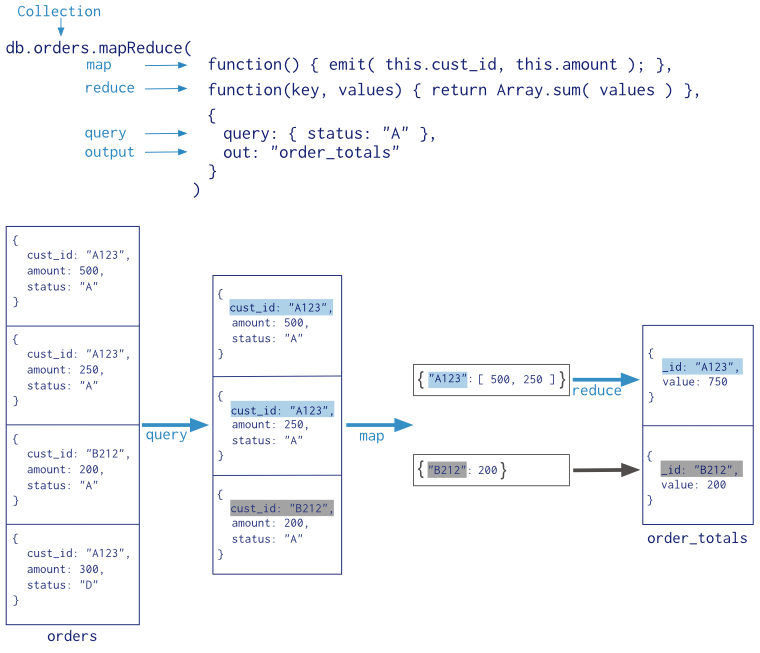
>db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将key与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
- map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce :(规约)统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。
- out :统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query :一个筛选条件,只有满足条件的文档才会调用map函数。(query,limit,sort可以随意组合)
- sort :和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit :执行map函数之前,限定文档数量的上限(要是没有limit,单独使用sort的用处不大)
MR示例
现有集合 orders 内容如下
db.orders.insert([
{
_id: 1,
cust_id: "marong",
ord_date: new Date("Oct 04, 2012"),
status: 'A',
items: [ { sku: "mmm", qty: 5, price: 2.5 },
{ sku: "nnn", qty: 5, price: 2.5 } ]
},
{
_id: 2,
cust_id: "marong",
ord_date: new Date("Oct 05, 2012"),
status: 'B',
items: [ { sku: "mmm", qty: 5, price: 3 },
{ sku: "nnn", qty: 5, price: 3 } ]
}
])
计算每个客户的总消费
执行过程:

1. 执行 map 操作过程
- 定义
map(映射) 函数来处理每个文档: - 映射每个文档的
cust_id, 并处理items - 先遍历
items,分别对每个items成员qty和price相乘再求总和
var mapFunction2 = function() {
var key = this.cust_id;
var value = 0;
for (var idx = 0; idx < this.items.length; idx++) {
value += this.items[idx].qty * this.items[idx].price;
}
emit(key, value);
};
2. 定义reduce 函数有两个参数 keyCustId 和 valuesPrices
valuesPrices是数组,由keyCustId分组, 收集value而来reduces函数 对valuesPrices数组 求和.
var reduceFunction2 = function(keyCustId, valuesPrices) {
return Array.sum(valuesPrices);
};
3. 执行 map-reduce 函数
db.orders.mapReduce(
mapFunction2,
reduceFunction2,
{ out: "map_reduce_example" }
)