http://blog.nosqlfan.com/html/4117.html
我们知道,MongoDB的索引是B-Tree结构的,和MySQL的索引非常类似。所以你应该听过这样的建议:创建索引的时候要考虑到sort操作,尽量把sort操作要用到的字段放到你的索引后面。但是有的情况下,这样做反而会使你的查询性能更低。
问题
比如我们进行下面这样的查询:
db.collection.find({"country": "A"}).sort({"carsOwned": 1})
查询条件是 {“country”: “A”},按 carsOwned 字段的正序排序。所以索引就很好建了,直接建立 country , carsOwned 两个字段的联合索引即可。像这样:
db.collection.ensureIndex({"country": 1, "carsOwned": 1})
我们来看一个稍微复杂一点的查询:
db.collection.find({"country": {"$in": ["A", "G"]}}).sort({"carsOwned": 1})
这回我们是要查询 country 为 A 或者 G 的数据条目,结果同样按 carsOwned 字段排序。
如果我们还使用上面的索引,并且使用 explain() 分析一下这个查询,就会发现在输出中有一个“scanAndOrder” : true 的字段,并且 nscanned 的值可能会比想象中的大很多,甚至指定了 limit 也没什么效果。
原因
这是什么原因呢,我们先看下面这张图:
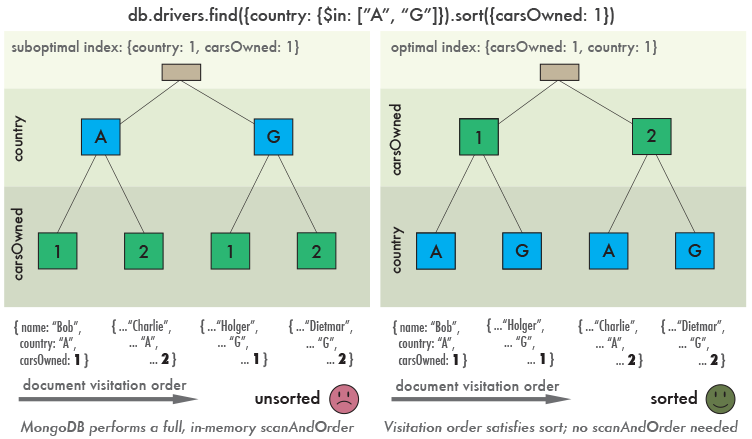
如上图所未,左边一个是按 {“country”: 1, “carsOwned”: 1} 的顺序建立的索引。而右边是按{“carsOwned”: 1, ”country”: 1} 顺序建立的索引。
如果我们执行上面的查询,通过左边的索引,我们需要将 country 值为A的(左图的左边一支)所有子节点以及country 值为G的(左图的右边一支)所有子节点都取也来。然后再对取出来的这些数据按 carsOwned 值进行一次排序操作。
所以说上面 explain 输出了一个 “scanAndOrder” : true 的提示,就是说这次查询,是先进行了scan获取到数据,再进行了独立的排序操作的。
那如果我们使用右边的索引来做查询,结果就不太一样了。我们没有将排序字段放在最后,而是放在了前面,相反把筛选字段放在了后面。那这样的结果就是:我们 会从值为1的节点开始遍历(右图的左边一支),当发现有 country 值为 A 或 G 的,就直接放到结果集中。当完成指定数量(指定 limit 个数)的查找后。我们就可以直接将结果返回了,因为这时候,所有的结果本身就是按 carsOwned 正序排列的。
对于上面的数据集,如果我们需要2条结果。我们通过左图的索引需要扫描到4条记录,然后对4条记录进行排序才能返回结果。而右边只需要我们扫描2条结果就能直接返回了(因为查询的过程就是按需要的顺序去遍历索引的)。
所以,在有范围查询(包括$in, $gt, $lt 等等)的时候,其实刻意在后面追加排序索引通常是没有效果的。因为在进行范围查询的过程中,我们得到的结果集本身并不是按追加的这个字段来排的,还需要进 行一次额外的排序才行。而在这种情况下,可能反序建立索引(排序字段在前、范围查询字段在后)反而会是一个比较优的选择。当然,是否更优也和具体的数据集 有关。
总结
总结一下,举两个栗子。
当查询是:
db.test.find({a:1,b:2}).sort({c:1})
那么直接建立 {a:1, b:1, c:1} 或者 {b:1, a:1, c:1} 的联合索引即可。
如果查询是:
db.test.find({a:1,b:{$in:[1,2]}}).sort({c:1})
那么可能建立 {a:1, c:1, b:1} 的联合索引会比较合适。当然,这里只是提供了多一种思路,具体是否采用还是需要视你的数据情况而定。
索引特性
组合索引有许多特性要记住。
下面的例子都假想在 a, b, c上创建组合索引。因此创建索引语句如下
db.foo.ensureIndex({a: 1, b: 1, c: 1})
1. 排序的列一定要在索引的最后。
好的:
find(a=1).sort(a)
find(a=1).sort(b)
find(a=1, b=2).sort(c)
不好的:
find(a=1).sort(c)
即使c是索引的最后一列,a列是所使用的最后一列,因此你只能通过a或者b列进行排序。