页面解析之结构化数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据,提取JSON的关键字段即可。
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式;适用于进行数据交互的场景,比如网站前台与后台之间的数据交互
Python 2.7中自带了JSON模块,直接import json就可以使用了。
Json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换
1. json.loads()
实现:json字符串 转化 python的类型,返回一个python的类型
从json到python的类型转化对照如下:
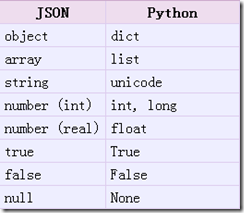
import json
a="[1,2,3,4]"
b='{"k1":1,"k2":2}'#当字符串为字典时{}外面必须是''单引号{}里面必须是""双引号
print json.loads(a)
[1, 2, 3, 4]
print json.loads(b)
{'k2': 2, 'k1': 1}
案例
import urllib2
import json
response = urllib2.urlopen(r'http://api.douban.com/v2/book/isbn/9787218087351')
hjson = json.loads(response.read())
print hjson.keys()
print hjson['rating']
print hjson['images']['large']
print hjson['summary']
2. json.dumps()
实现python类型转化为json字符串,返回一个str对象
从python原始类型向json类型的转化对照如下:
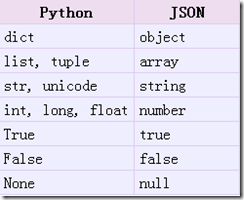
import json
a = [1,2,3,4]
b ={"k1":1,"k2":2}
c = (1,2,3,4)
json.dumps(a)
'[1, 2, 3, 4]'
json.dumps(b)
'{"k2": 2, "k1": 1}'
json.dumps(c)
'[1, 2, 3, 4]'
json.dumps 中的ensure_ascii 参数引起的中文编码问题
如果Python Dict字典含有中文,json.dumps 序列化时对中文默认使用的ascii编码
import chardet
import json
b = {"name":"中国"}
json.dumps(b)
'{"name": "\\u4e2d\\u56fd"}'
print json.dumps(b)
{"name": "\u4e2d\u56fd"}
chardet.detect(json.dumps(b))
{'confidence': 1.0, 'encoding': 'ascii'}
'中国' 中的ascii 字符码,而不是真正的中文。
想输出真正的中文需要指定ensure_ascii=False
json.dumps(b,ensure_ascii=False)
'{"name": "\xe6\x88\x91"}'
print json.dumps(b,ensure_ascii=False)
{"name": "我"}
chardet.detect(json.dumps(b,ensure_ascii=False))
{'confidence': 0.7525, 'encoding': 'utf-8'}
3. json.dump()
把Python类型 以 字符串的形式 写到文件中
import json
a = [1,2,3,4]
json.dump(a,open("digital.json","w"))
b = {"name":"我"}
json.dump(b,open("name.json","w"),ensure_ascii=False)
json.dump(b,open("name2.json","w"),ensure_ascii=True)
4. json.load()
读取 文件中json形式的字符串元素 转化成python类型
# -*- coding: utf-8 -*-
import json
number = json.load(open("digital.json"))
print number
b = json.load(open("name.json"))
print b
b.keys()
print b['name']
实战项目
获取 lagou 城市表信息
import urllib2
import json
import chardet
url ='http://www.lagou.com/lbs/getAllCitySearchLabels.json?'
request =urllib2.Request(url)
response = urllib2.urlopen(request)
print response.code
resHtml = response.read()
jsonobj = json.loads(resHtml)
print type(jsonobj)
print jsonobj
citylist =[]
allcitys = jsonobj['content']['data']['allCitySearchLabels']
print allcitys.keys()
for key in allcitys:
print type(allcitys[key])
for item in allcitys[key]:
name =item['name'].encode('utf-8')
print name,type(name)
citylist.append(name)
fp = open('city.json','w')
content = json.dumps(citylist,ensure_ascii=False)
print content
fp.write(content)
fp.close()
输出:
JSONPath
JSON 信息抽取类库,从JSON文档中抽取指定信息的工具
JSONPath与Xpath区别
JsonPath 对于 JSON 来说,相当于 XPATH 对于XML。
下载地址:
https://pypi.python.org/pypi/jsonpath/
安装方法:
下载jsonpath,解压之后执行'python setup.py install'
| XPath | JSONPath | Result |
/store/book/author | $.store.book[*].author | the authors of all books in the store |
//author | $..author | all authors |
/store/* | $.store.* | all things in store, which are some books and a red bicycle. |
/store//price | $.store..price | the price of everything in the store. |
//book[3] | $..book[2] | the third book |
//book[last()] | $..book[(@.length-1)]$..book[-1:] | the last book in order. |
//book[position()<3] | $..book[0,1]$..book[:2] | the first two books |
//book[isbn] | $..book[?(@.isbn)] | filter all books with isbn number |
//book[price<10] | $..book[?(@.price<10)] | filter all books cheapier than 10 |
//* | $..* | all Elements in XML document. All members of JSON structure. |
案例
还是以 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市
import jsonpath
import urllib2
import chardet
url ='http://www.lagou.com/lbs/getAllCitySearchLabels.json'
request =urllib2.Request(url)
response = urllib2.urlopen(request)
print response.code
resHtml = response.read()
##detect charset
print chardet.detect(resHtml)
jsonobj = json.loads(resHtml)
citylist = jsonpath.jsonpath(jsonobj,'$..name')
print citylist
print type(citylist)
fp = open('city.json','w')
content = json.dumps(citylist,ensure_ascii=False)
print content
fp.write(content.encode('utf-8'))
fp.close()
XML
xmltodict模块让使用XML感觉跟操作JSON一样
Python操作XML的第三方库参考:
https://github.com/martinblech/xmltodict
模块安装:
pip install xmltodict
import xmltodict
bookdict = xmltodict.parse("""
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
""")
print bookdict.keys()
[u'bookstore']
print json.dumps(bookdict,indent=4)
输出结果:
{
"bookstore": {
"book": [
{
"title": {
"@lang": "eng",
"#text": "Harry Potter"
},
"price": "29.99"
},
{
"title": {
"@lang": "eng",
"#text": "Learning XML"
},
"price": "39.95"
}
]
}
}
数据提取总结
HTML、XML
XPath CSS选择器 正则表达式JSON
JSONPath 转化成Python类型进行操作(json类)XML
转化成Python类型(xmltodict) XPath CSS选择器 正则表达式其他(js、文本、电话号码、邮箱地址)
正则表达式