海量数据处理算法Bloom Filter
Bloom-Filter,即布隆过滤器,1970年由Bloom中提出。是一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
Bloom Filter有可能会出现错误判断,但不会漏掉判断。
也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误
因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter比其他常见的算法(如hash,折半查找)极大节省了空间。 它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
一. 实例
为了说明Bloom Filter存在的重要意义,举一个实例:
假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道蜘蛛已经访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,就会有如下几种方案:
1. 将访问过的URL保存到数据库。
2. 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
3. URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。
4. Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。
以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。
方法1的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?
方法2的缺点:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。
方法3:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。
方法4:消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将BitSet的长度设置为URL个数的100倍。
实质上上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要100%准确!也就是说少量url实际上没有没网络蜘蛛访问,而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。
二. Bloom Filter的算法
废话说到这里,下面引入本篇的主角——Bloom Filter。其实上面方法4的思想已经很接近Bloom Filter了。方法四的致命缺点是冲突概率高,为了降低冲突的概念,Bloom Filter使用了多个哈希函数,而不是一个。
Bloom Filter算法如下:
创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。
(1) 加入字符串过程
下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。

图1.Bloom Filter加入字符串过程
很简单吧?这样就将字符串str映射到BitSet中的k个二进制位了。
(2) 检查字符串是否存在的过程
下面是检查字符串str是否被BitSet记录过的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive 。
三. Bloom Filter参数选择
(1)哈希函数选择
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
(2) m,n,k值,我们如何取值
我们定义:
可能把不属于这个集合的元素误认为属于这个集合(False Positive)
不会把属于这个集合的元素误认为不属于这个集合(False Negative)。
哈希函数的个数k、位数组大小m、加入的字符串数量n的关系。哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,即10万次的判断中,会存在9次误判,对于一天1亿次的查询,误判的次数为9000次。
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考参考文献(http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html)。
| m/n | k | k=17 | k=18 | k=19 | k=20 | k=21 | k=22 | k=23 | k=24 |
| 22 | 15.2 | 2.67e-05 | |||||||
| 23 | 15.9 | 1.61e-05 | |||||||
| 24 | 16.6 | 9.84e-06 | 1e-05 | ||||||
| 25 | 17.3 | 6.08e-06 | 6.11e-06 | 6.27e-06 | |||||
| 26 | 18 | 3.81e-06 | 3.76e-06 | 3.8e-06 | 3.92e-06 | ||||
| 27 | 18.7 | 2.41e-06 | 2.34e-06 | 2.33e-06 | 2.37e-06 | ||||
| 28 | 19.4 | 1.54e-06 | 1.47e-06 | 1.44e-06 | 1.44e-06 | 1.48e-06 | |||
| 29 | 20.1 | 9.96e-07 | 9.35e-07 | 9.01e-07 | 8.89e-07 | 8.96e-07 | 9.21e-07 | ||
| 30 | 20.8 | 6.5e-07 | 6e-07 | 5.69e-07 | 5.54e-07 | 5.5e-07 | 5.58e-07 | ||
| 31 | 21.5 | 4.29e-07 | 3.89e-07 | 3.63e-07 | 3.48e-07 | 3.41e-07 | 3.41e-07 | 3.48e-07 | |
| 32 | 22.2 | 2.85e-07 | 2.55e-07 | 2.34e-07 | 2.21e-07 | 2.13e-07 | 2.1e-07 | 2.12e-07 | 2.17e-07 |
该文献证明了对于给定的m、n,当 k = ln(2)* m/n 时出错的概率是最小的。(log2 e ≈ 1.44倍)
同时该文献还给出特定的k,m,n的出错概率。例如:根据参考文献1,哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,这个概率基本能满足网络爬虫的需求了。
四.Python实现Bloom filter
官方文档:
http://axiak.github.io/pybloomfiltermmap/index.html
https://github.com/axiak/pybloomfiltermmap
安装:
sudo apt-get install libssl-dev
sudo pip install pybloomfiltermmap==0.2.0
sudo pip install pybloomfiltermmap==0.3.12
Here’s a quick example:
from pybloomfilter import BloomFilter
bf = BloomFilter(10000000, 0.01, 'filter.bloom')
with open("/usr/share/dict/words") as f:
for word in f:
bf.add(word.rstrip())
print 'apple' in bf
#outputs True
>>> fruit = pybloomfilter.BloomFilter(100000, 0.1, '/tmp/words.bloom')
>>> fruit.extend(('apple', 'pear', 'orange', 'apple'))
>>> len(fruit)
3
>>> 'mike' in fruit
False
fruitbf = bf.copy_template("fruit.bloom")
fruitbf.update(("apple", "banana", "orange", "pear"))
print fruitbf.to_base64()
"eJzt2k13ojAUBuA9f8WFyofF5TWChlTHaPzqrlqFCtj6gQi/frqZM2N7aq3Gis59d2ye85KTRbhk"
"0lyu1NRmsQrgRda0I+wZCfXIaxuWv+jqDxA8vdaf21HIOSn1u6LRE0VL9Z/qghfbBmxZoHsqM3k8"
"N5XyPAxH2p22TJJoqwU9Q0y0dNDYrOHBIa3BwuznapG+KZZq69JUG0zu1tqI5weJKdpGq7PNJ6tB"
"GKmzcGWWy8o0FeNNYNZAQpSdJwajt7eRhJ2YM2NOkTnSsBOCGGKIIYbY2TA663GgWWyWfUwn3oIc"
"fyLYxeQwiF07RqBg9NgHrG5ba3jba5yl4zS2LtEMMcQQQwwxmRiBhPGOJOywIPafYhUwqnTvZOfY"
"Zu40HH/YxDexZojJwsx6ObDcT7D8vVOtJBxiAhD/AjMmjeF2Wnqd+5RrHdo4azPEzoANabiUhh0b"
"xBBDDDHEENsf8twlrizswEjDhnTbzWazbGKpQ5k07E9Ox2iFvXBZ2D9B7DawyqLFu5lshhhiiGUK"
"a4nUloa9yxkwR7XhgPPXYdhRIa77uDtnyvqaIXalGK02ufv3J36GmsnG4lquPnN9gJo1VNxqgYbt"
"ji/EC8s1PWG5fuVizW4Jox6/3o9XxBBDDLFbwcg9v/AwjrPHtTRsX34O01mxLw37bhCTjJk0+PLK"
"08HYd4MYYojdKmYnBfjsktEpySY2tGGZzWaIIfYDGB271Yaieaat/AaOkNKb"
>>> bf = BloomFilter.from_base64("/tmp/mike.bf",
"eJwFwcuWgiAAANC9v+JCx7By0QKt0GHEbKSknflAQ9QmTyRfP/fW5E9XTRSX"
"qcLlqGNXphAqcfVH\nRoNv0n4JlTpIvAP0e1+RyXX6I637ggA+VPZnTYR1A4"
"Um5s9geYaZZLiT208JIiG3iwhf3Fwlzb3Y\n5NRL4uNQS6/d9OvTDJbnZMnR"
"zcrplOX5kmsVIkQziM+vw4hCDQ3OkN9m3WVfPWzGfaTeRftMCLws\nPnzEzs"
"gjAW60xZTBbj/bOAgYbK50PqjdzvgHZ6FHZw==\n")
>>> "MIKE" in bf
True
BloomFilter.copy_template(filename[, perm=0755]) → BloomFilter Creates a new BloomFilter object with the same parameters–same hash seeds, same size.. everything. Once this is performed, the two filters are comparable, so you can perform logical operators. Example:
>>> apple = BloomFilter(100, 0.1, '/tmp/apple')
>>> apple.add('apple')
False
>>> pear = apple.copy_template('/tmp/pear')
>>> pear.add('pear')
False
>>> pear |= apple
BloomFilter.len(item) → Integer Returns the number of distinct elements that have been added to the BloomFilter object, subject to the error given in error_rate.
>>> bf = BloomFilter(100, 0.1, '/tmp/fruit.bloom')
>>> bf.add("Apple")
>>> bf.add('Apple')
>>> bf.add('orange')
>>> len(bf)
2
>>> bf2 = bf.copy_template('/tmp/new.bloom')
>>> bf2 |= bf
>>> len(bf2)
Traceback (most recent call last):
...
pybloomfilter.IndeterminateCountError: Length of BloomFilter object is unavailable after intersection or union called.
五:Bloom Filter的优缺点。
优点:
节约缓存空间(空值的映射),不再需要空值映射。
减少数据库或缓存的请求次数。
提升业务的处理效率以及业务隔离性。
缺点:
存在误判的概率。
传统的Bloom Filter不能作删除操作。
六:Bloom-Filter的应用场景
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
(1)适用于一些黑名单,垃圾邮件等的过滤,例如邮件服务器中的垃圾邮件过滤器。
像网易,QQ这样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。
一个办法就是记录下那些发垃圾邮件的 email地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。
而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
BloomFilter决不会漏掉任何一个在黑名单中的可疑地址。而至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能别误判的邮件地址。
(2)在搜索引擎领域,Bloom-Filter最常用于网络蜘蛛(Spider)的URL过滤,网络蜘蛛通常有一个URL列表,保存着将要下载和已经下载的网页的URL,网络蜘蛛下载了一个网页,从网页中提取到新的URL后,需要判断该URL是否已经存在于列表中。此时,Bloom-Filter算法是最好的选择。
2 .Google的BigTable Google的BigTable也使用了Bloom Filter,以减少不存在的行或列在磁盘上的查询,大大提高了数据库的查询操作的性能。
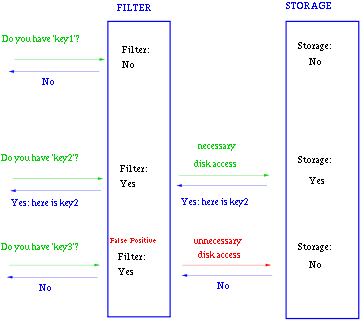
3.key-value 加快查询 一般Bloom-Filter可以与一些key-value的数据库一起使用,来加快查询。
一般key-value存储系统的values存在硬盘,查询就是件费时的事。将Storage的数据都插入Filter,在Filter中查询都不存在时,那就不需要去Storage查询了。当False Position出现时,只是会导致一次多余的Storage查询。
由于Bloom-Filter所用的空间非常小,所有BF可以常驻内存。这样子的话,对于大部分不存在的元素,我们只需要访问内存中的Bloom-Filter就可以判断出来了,只有一小部分,我们需要访问在硬盘上的key-value数据库。从而大大地提高了效率。如图: