简单来说,“HTTP 隧道技术”就是把所有要传送的数据全部封装到 HTTP 协议里进行传送,HTTP隧道技术几乎支持了所有的上网方式,如:拨号上网、ADSL、Cable Modem、NAT透明代理、HTTP的GET型和CONNECT型代理、SOCKS4代理、SOCKS5代理等。
另外HTTP隧道技术也用于木马的制作,如把HTTP数据包里Agent段设为IE,对外端口为80,然后把自己的小马注入IE进程,哪个防火墙能分辨出它是木马在发送数据?
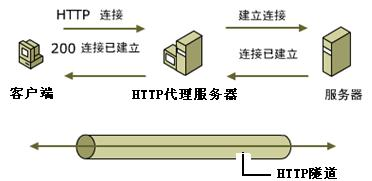
通过HTTP协议与代理服务器建立连接,协议信令中包含要连接到的远程主机的IP和端口号,如果有需要身份验证的话还需要加上授权信息,服务器收到信令后首先进行身份验证,通过后便与远程主机建立连接,连接成功之后会返回给客户端200,表示验证通过,就这么简单,下面是具体的信令格式:
CONNECT 124.xxx.xxx.xx:443 HTTP/1.1 //建立http隧道要443端口 Proxy-Connection: Keep-Alive //客户端到服务器端的连接持续有效 Content-Length: 0 Host: 124.xxx.xxx.xx //主机地址 Proxy-Authorization:Basic YTph //身份验证信息 User-Agent: OpenFetion //可以标识请求者的信息,如什么浏览器类型和版本、操作系统、使用语言等信息其中Proxy-Authorization是身份验证信息,Basic后面的字符串是用户名和密码组合后进行base64编码的结果,也就是对username:password进行base64编码。
其实编码对安全性没什么意义,base64严格意义上都已经不能算是加密了,现在信息安全这么受重视的年代,不需要密钥的加密[算法](http://lib.csdn.net/base/datastructure)还是叫编码更贴切一些,抓到这种包之后瞬间就可以得到用户名和密码。
HTTP/1.0 200 Connection established
客户端收到收面的信令后表示成功建立连接,接下来要发送给远程主机的数据就可以发送给代理服务器了,代理服务器建立连接后会在根据IP地址和端口号对应的连接放入缓存,收到信令后再根据IP地址和端口号从缓存中找到对应的连接,将数据通过该连接转发出去。
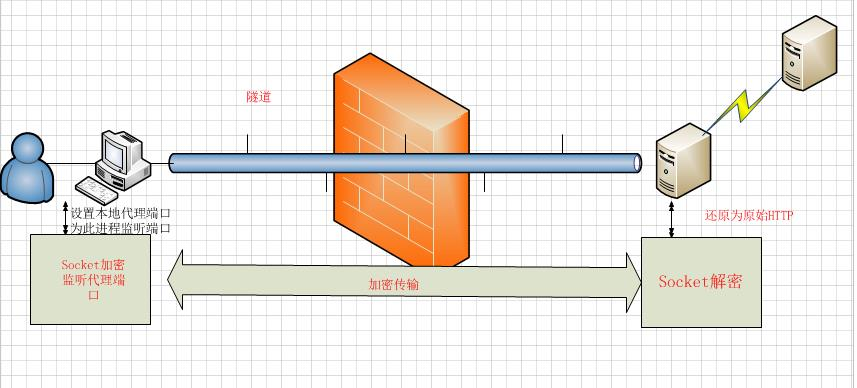
说到HTTP代理,在设置浏览器的本地代理时候会修改系统注册表项,修改后系统凡是HTTP/HTTPS协议都会把转发扔到设置的代理的对应端口。好了,那么切入点就在这里了,我们只需要监听一个本地端口,让系统把所有的请求全部转发到此端口,那么我们就可以获取所有的HTTP请求了,得到此请求我们需要将请求加密后传输到服务端,服务端解析得到原始HTTP后转发到真正的服务器,返回的时候也是一样的原理。同事问我这个是HTTP代理还是socket代理,我自己都不太说得清,杂交品种。
千言万语不如一张图:
HTTP proxy是怎么工作的?
在HTTP tunnel出来之前,HTTP proxy工作在中间人模式。
也就是说在一次请求中,客户端(浏览器)明文的请求代理服务器。代理服务器明文去请求远端服务器(网站),拿到返回结果,再将返回结果返回给客户端。整个过程对代理服务器来说都是可见的,代理能看到你要请求的path,你请求中的header(包括例如auth头里面的用户名密码),代理也能看到网站返回给你的cookie。和中间人攻击的中间人是一种情况(笑)
这种模式要求代理对请求进行适当的改写,RFC2616 5.1.2中要求请求代理的报文中Request-URI必须使用绝对路径,这样代理才能从中解出真正请求的目标,然后代理需要对这个请求进行改写再发送给远端服务器。
例如浏览器在不使用HTTP proxy时,发送的请求如下(省略了和示例无关的header,下同):
GET / HTTP/1.1\r\n
Host: stackoverflow.com\r\n
Connection: keep-alive\r\n
\r\n
使用了代理后,发送的报文将变为:
GET http://stackoverflow.com/ HTTP/1.1\r\n Host: stackoverflow.com\r\n Proxy-Connection: keep-alive\r\n \r\n
代理从请求的第一行中得知要请求的目标是stackoverflow.com,端口为默认端口(80),将第一行改写后,向网站服务器发送请求:
GET / HTTP/1.1\r\n Host: stackoverflow.com\r\n Connection: keep-alive\r\n \r\n
顺带一提上面这个例子可以看到有一个Proxy-Connection的header也被改写了,这个是HTTP/1.1的一个黑历史,现在它已经不是标准header了,并在RFC7230中被建议不要使用。然而现在浏览器(比如chrome)仍然在发送这个header,因此代理服务器还是要对它做处理,处理方式就是当做Connection header改写后发送给远端。
为什么需要HTTP tunnel?
从前一条可以看出,如果我们想在复用现有的HTTP proxy的传输方式来代理HTTPS流量,那么就会变成浏览器和代理握手跑TLS,代理拿到明文的请求报文,代理和网站握手跑TLS。
但是代理没有,也不可能有网站的私钥证书,所以这么做会导致浏览器和代理之间的TLS无法建立,证书校验根本通不过。
HTTP tunnel以及CONNECT报文解决了这个问题,代理服务器不再作为中间人,不再改写浏览器的请求,而是把浏览器和远端服务器之间通信的数据原样透传,这样浏览器就可以直接和远端服务器进行TLS握手并传输加密的数据。
HTTP tunnel的工作流程是什么样的?
普通的一次HTTP请求,header部分以连续两组CRLF(\r\n)作为标记结束,如果后面还有内容,也就是content部分的话,需要在header里面加入Content-Length头,值为content部分有多长,通信的对方(无论是服务器,还是接收服务器返回结果时的客户端)会按照这个长度来读后面那么多个byte,数写错了就跑飞了(笑)
对于CONNECT报文的请求,是没有content部分的,只有Request-Line和header。Request-Line和header均为仅供代理服务器使用的,不能传给远端服务器。请求的header部分一旦结束(连续的两组CRLF),后面所有的数据都被视为应该发给远端服务器(网站)的数据,代理需要把它们直接转发,而且不限长度,直到从客户端的TCP读通道关闭。
对于CONNECT报文的返回值,代理服务器在和远端服务器成功建立连接后,可以(标准说的是可以,但是一般都会)向客户端(浏览器)返回任意一个2xx状态码,此时表示含义是和远端服务器建立连接成功,这个2xx返回报文的header部分一旦结束(连续的两组CRLF),后面所有的数据均为远端服务器返回的数据,同理代理会直接转发远端服务器的返回数据给客户端,直到从远端服务器的TCP读通道关闭。