运行项目
这个项目演示了在多个spiders实例之间,如何共享(share)一个爬虫spider的请求队列;
第一次运行的爬虫,然后停止它:
cd redis-youyuan scrapy crawl youyuan ... [youyuan] ... ^C重新运行停止的爬虫:
scrapy crawl youyuan 2016-08-22 22:32:04 [youyuan] DEBUG: Resuming crawl (13 requests scheduled)启动一个或更多的scrapy爬虫:
scrapy crawl youyuan ... [dmoz] DEBUG: Resuming crawl (8712 requests scheduled)
过程分析
假定有两个爬虫,那么是如何实现分布式,具体的步骤如下:
1) 首先运行爬虫A
爬虫A中start_urls push 待下载request队列、调度器从待下载request队列取出一个request,交给spider下载,spider根据定义的rules得到链接,然后把链接push到redis request队列中。
备注:待下载request队列是redis 队列实现的,也就是将生成request(url)push到queue中,(调度器)请求时pop出来。
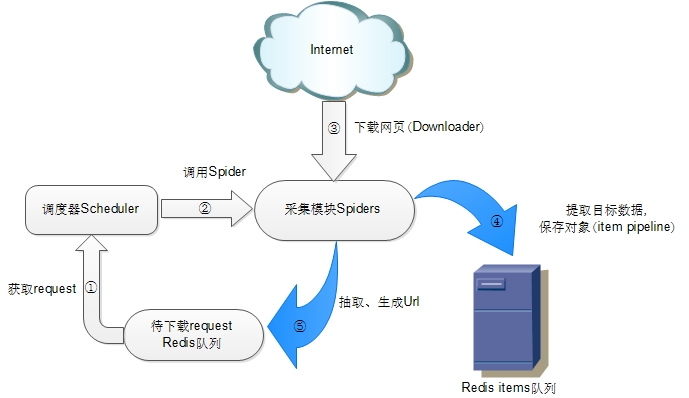
2) 停止爬虫A, 重新运行爬虫A、B
爬虫 A 和 B 同时到 待下载request队列中取request任务,等待下载request完成之后,爬虫A和B 各自下载自定义的链接(比如start_urls,一般来讲,此时大部分请求连接都被去重,任务基本完成)。
备注:在scrapy-redis中 待下载request队列 默认使用的是SpiderPriorityQueue方式,这是由sorted set实现的一种非FIFO,LIFO方式。
注意
每次执行重新爬取时,应该将redis中存储的数据清空,否则会影响爬虫运行。