学习爬虫的正确打开方式
看了大部分回答不禁叹口气,主要是因为看到很多大牛在回答像“如何入门爬虫”这种问题的时候,一如当年学霸讲解题目,跳步无数,然后留下一句“不就是这样推嘛”,让一众小白菜鸟一脸懵逼。。作为一个0起步(之前连python都不会),目前总算掌握基础,开始向上进阶的菜鸟,深知其中的不易,所以我会在这个回答里,尽可能全面、细节地分享给大家从0学习爬虫的各种步骤,如果对你有帮助,请点赞~
首先!你要对爬虫有个明确的认识,这里引用毛主席的思想:

在战略上藐视:
“所有网站皆可爬”:互联网的内容都是人写出来的,而且都是偷懒写出来的(不会第一页是a,下一页是8),所以肯定有规律,这就给人有了爬取的可能,可以说,天下没有不能爬的网站 “框架不变”:网站不同,但是原理都类似,大部分爬虫都是从 发送请求——获得页面——解析页面——下载内容——储存内容 这样的流程来进行,只是用的工具不同
在战术上重视:
持之以恒,戒骄戒躁:对于初学入门,不可轻易自满,以为爬了一点内容就什么都会爬了,爬虫虽然是比较简单的技术,但是往深学也是没有止境的(比如搜索引擎等)!只有不断尝试,刻苦钻研才是王道!(为何有种小学作文即视感)
||
||
V
然后,你需要一个宏伟的目标,来让你有持续学习的动力(没有实操项目,真的很难有动力)
我要爬整个豆瓣!...
我要爬整个草榴社区!
我要爬知乎各种妹子的联系方式*&^#%^$#

接着,你需要扪心自问一下,自己的python基本功吼不吼啊?
吼啊!——OK,开始欢快地学习爬虫吧 !
不吼?你还需要学习一个!赶紧回去看Python核心编程教程。至少这些功能和语法你要有基本的掌握 : list,dict:用来序列化你爬的东西 切片:用来对爬取的内容进行分割,生成 条件判断(if等):用来解决爬虫过程中哪些要哪些不要的问题 循环和迭代(for while ):用来循环,重复爬虫动作 文件读写操作:用来读取参数、保存爬下来的内容等
||
||
V
然后,你需要补充一下下面几个内容,作为你的知识储备:
(注:这里并非要求“掌握”,下面讲的两点,只需要先了解,然后通过具体项目来不断实践,直到熟练掌握)
1、网页的基本知识:
基本的HTML语言知识(知道href等大学计算机一级内容即可)
理解网站的发包和收包的概念(POST GET)
稍微一点点的js知识,用于理解动态网页(当然如果本身就懂当然更好啦)
2、一些分析语言,为接下来解析网页内容做准备
NO.1 正则表达式:扛把子技术,总得会最基础的:

NO.2 XPATH:高效的分析语言,表达清晰简单,掌握了以后基本可以不用正则
参考:XPath 教程[http://link.zhihu.com/?target=http%3A//www.w3school.com.cn/xpath/]

NO.3 Beautifulsoup:
美丽汤模块解析网页神器,一款神器,如果不用一些爬虫框架(如后文讲到的scrapy),配合request,urllib等模块(后面会详细讲),可以编写各种小巧精干的爬虫脚本
官网文档:Beautiful Soup 4.2.0 文档[http://link.zhihu.com/?target=http%3A//beautifulsoup.readthedocs.org/zh_CN/latest/]
参考案例:
||
||
V
接着,你需要一些高效的工具来辅助
(同样,这里先了解,到具体的项目的时候,再熟悉运用)
NO.1 F12 开发者工具:
看源代码:快速定位元素
分析xpath:1、此处建议谷歌系浏览器,可以在源码界面直接右键看

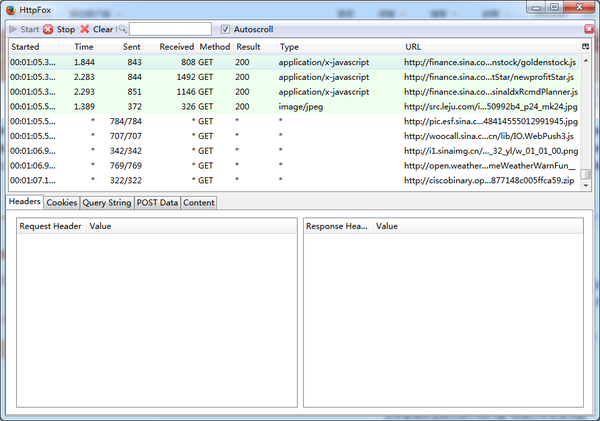
NO.2 抓包工具:
推荐httpfox,火狐浏览器下的插件,比谷歌火狐系自带的F12工具都要好,可以方便查看网站收包发包的信息
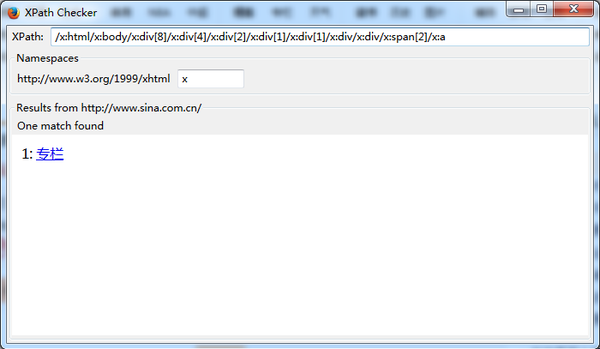
NO.3 XPATH CHECKER (火狐插件):
非常不错的xpath测试工具,但是有几个坑,都是个人踩过的,,在此告诫大家:
1、xpath checker生成的是绝对路径,遇到一些动态生成的图标(常见的有列表翻页按钮等),飘忽不定的绝对路径很有可能造成错误,所以这里建议在真正分析的时候,只是作为参考
2、记得把如下图xpath框里的“x:”去掉,貌似这个是早期版本xpath的语法,目前已经和一些模块不兼容(比如scrapy),还是删去避免报错
NO.4 正则表达测试工具:
在线正则表达式测试(http://link.zhihu.com/?target=http%3A//tool.oschina.net/regex/) ,拿来多练练手,也辅助分析!里面有很多现成的正则表达式可以用,也可以进行参考!
||
||
V ok!这些你都基本有一些了解了,现在开始进入抓取时间,上各种模块吧!python的火,很大原因就是各种好用的模块,这些模块是居家旅行爬网站常备的——
urllib
urllib2
requests
||
||
V
**不想重复造轮子,有没有现成的框架?
华丽丽的scrapy(这块我会重点讲,我的最爱)**
||
||
V
遇到动态页面怎么办?
selenium(会了这个配合scrapy无往不利,是居家旅行爬网站又一神器,下一版更新的时候会着重安利,因为这块貌似目前网上的教程还很少)
||
||
V
爬来的东西怎么用?
pandas(基于numpy的数据分析模块,相信我,如果你不是专门搞TB级数据的,这个就够了)
||
||
V
然后是数据库,这里我认为开始并不需要非常深入,在需要的时候再学习即可
mysql
mongodb
sqllite
遇到反爬虫策略验证码之类咋整?
PIL
opencv
pybrain
||
||
V
进阶技术
多线程、分布式
———————————— 乱入的分割线 —————————————
然后学习编程关键的是学以致用,天天捧一本书看不如直接上手操练,下面我通过实际的例子来讲解爬虫—— 比如最近,楼主在豆瓣上认识了一个很有趣的妹子,发现她一直会更新签名和日志,所以没事就会去她主页看看,但一直没有互相加好友(作为一只高冷的天蝎,怎么可以轻易加好友嘛!而且加了好友,你更新什么都会收到推送,那多没意思啊!一点神秘感都没有了!),可还是想及时获得妹子的最新动态,怎么办?

于是我就写了个70几行的python脚本,包含爬虫+邮件模块,通过windows计划任务每隔一小时自动抓取妹子的签名和最新文章一次,发送到我的邮箱。。嗯,其实是很简单的技术,,代码如下所示:
#-*-coding:utf-8-*- #编码声明,不要忘记!
import requests #这里使用requests,小脚本用它最合适!
from lxml import html #这里我们用lxml,也就是xpath的方法
#豆瓣模拟登录,最简单的是cookie,会这个方法,80%的登录网站可以搞定
cookie = {}
raw_cookies = ''#引号里面是你的cookie,用之前讲的抓包工具来获得
for line in raw_cookies.split(';'):
key,value = line.split("=", 1)
cookie[key] = value #一些格式化操作,用来装载cookies
#重点来了!用requests,装载cookies,请求网站
page = requests.get('#妹纸的豆瓣主页#',cookies=cookie)
#对获取到的page格式化操作,方便后面用XPath来解析
tree = html.fromstring(page.text)
#XPath解析,获得你要的文字段落!
intro_raw = tree.xpath('//span[@id="intro_display"]/text()')
#简单的转码工作,这步根据需要可以省略
for i in intro_raw:
intro = i.encode('utf-8')
print intro #妹子的签名就显示在屏幕上啦
#接下来就是装载邮件模块,因为与本问题关联不大就不赘述啦~