Scrapy-Redis 架构分析
scrapy任务调度是基于文件系统,这样只能在单机执行crawl。
scrapy-redis将待抓取request请求信息和数据items信息的存取放到redis queue里,使多台服务器可以同时执行crawl和items process,大大提升了数据爬取和处理的效率。
scrapy-redis是基于redis的scrapy组件,主要功能如下:
• 分布式爬虫
多个爬虫实例分享一个redis request队列,非常适合大范围多域名的爬虫集群
• 分布式后处理
爬虫抓取到的items push到一个redis items队列,这就意味着可以开启多个items processes来处理抓取到的数据,比如存储到Mongodb、Mysql
• 基于scrapy即插即用组件
Scheduler + Duplication Filter, Item Pipeline, Base Spiders.
scrapy原生架构
分析scrapy-redis的架构之前先回顾一下scrapy的架构
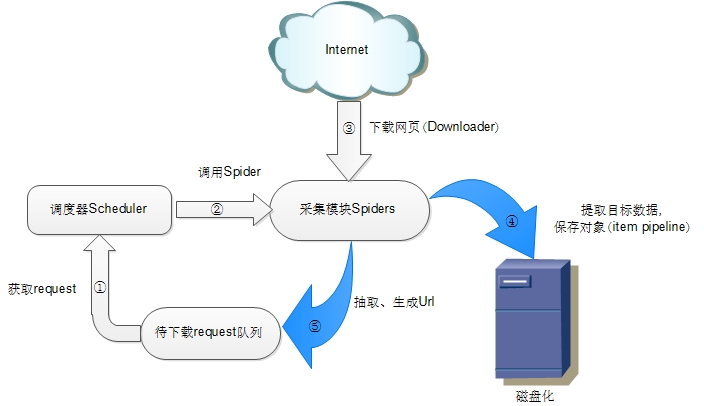
• 调度器(Scheduler)
调度器维护request 队列,每次执行取出一个request。
• Spiders
Spider是Scrapy用户编写用于分析response,提取item以及跟进额外的URL的类。
每个spider负责处理一个特定(或一些)网站。
• Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、验证数据及持久化(例如存取到数据库中)。
scrapy-redis 架构
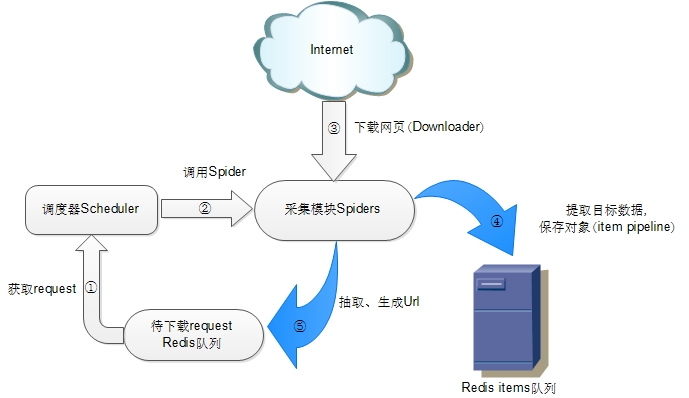
如上图所示,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
• 调度器(Scheduler)
scrapy-redis调度器通过redis的set不重复的特性,巧妙的实现了Duplication Filter去重(DupeFilter set存放爬取过的request)。
Spider新生成的request,将request的指纹到redis的DupeFilter set检查是否重复,并将不重复的request push写入redis的request队列。
调度器每次从redis的request队列里根据优先级pop出一个request, 将此request发给spider处理。
• Item Pipeline
将Spider爬取到的Item给scrapy-redis的Item Pipeline,将爬取到的Item存入redis的items队列。可以很方便的从items队列中提取item,从而实现items processes 集群
总结
scrapy-redis巧妙的利用redis 实现 request queue和 items queue,利用redis的set实现request的去重,将scrapy从单台机器扩展多台机器,实现较大规模的爬虫集群