1、大端与小端的概念?各自的优势是什么?
【答】大端与小端是用来描述多字节数据在内存中的存放顺序,即字节序。大端(Big Endian)是指低地址端存放高位字节,小端(Little Endian)是指低地址端存放低位字节。
- Big Endian:符号位的判定固定为第一个字节,容易判断正负。
- Little Endian:长度为1,2,4字节的数,排列方式都是一样的,数据类型转换非常方便。
2、TIME_WAIT状态的产生、危害、如何避免?
【答】TCP协议在关闭连接的四次挥手中,为了应对最后一个 ACK 丢失的情况,Client(即主动关闭连接的一方)需要维持 time_wait 状态并停留 2 个MSL的时间。
危害:Linux分配给一个用户的文件句柄是有限的,如果系统中存在大量的 time_wait 状态,一旦达到句柄数上限,新的请求就无法被处理了,而且大量 time_wait 连接占用资源影响性能。
如何避免:在/etc/sysctl.conf文件中开启net.ipv4.tcp_tw_reuse重用和net.ipv4.tcp_tw_recycle快速回收。
3、select / poll / epoll 的区别
| select | poll | epoll |
|---|---|---|
| 操作方式 | 遍历 | 遍历 |
| 底层实现 | 数组 | 链表 |
| IO效率 | 每次调用都进行线性遍历,时间复杂度为O(n) | 每次调用都进行线性遍历,时间复杂度为O(n) |
| 最大连接数 | 1024(x86)或 2048(x64) | 无上限 |
| fd拷贝 | 每次调用select,都需要把fd集合从用户态拷贝到内核态 | 每次调用poll,都需要把fd集合从用户态拷贝到内核态 |
4、系统调用与库函数的区别?
- 系统调用: 操作系统为用户程序与硬件设备进行交互提供的一组接口,发生在内核地址空间。
- 库函数: 把一些常用的函数编写完放到一个文件里,编写应用程序时调用,这是由第三方提供的,发生在用户地址空间。
- 在移植性方面,不同操作系统的系统调用一般是不同的,移植性差;而在所有的ANSI C编译器版本中,C库函数是相同的。
- 在调用开销方面,系统调用需要在用户空间和内核环境间切换,开销较大;而库函数调用属于“过程调用”,开销较小。
简单点说,库函数就是系统调用的上层封装,为了让应用程序在使用时更加方便。
5、守护、僵尸、孤儿进程的概念
- 守护进程: 运行在后台的一种特殊进程,独立于控制终端并周期性地执行某些任务。
- 僵尸进程:
一个进程 fork 子进程,子进程退出,而父进程没有
wait/waitpid子进程,那么子进程的进程描述符仍保存在系统中,这样的进程称为僵尸进程。 - 孤儿进程: 一个父进程退出,而它的一个或多个子进程还在运行,这些子进程称为孤儿进程。(孤儿进程将由 init 进程收养并对它们完成状态收集工作)
6、TCP 和 UDP 的区别?
TCP是稳定、可靠、面向连接的传输层协议,它在传递数据前要三次握手建立连接,在数据传递时,有确认机制、重传机制、流量控制、拥塞控制等,可以保证数据的正确性和有序性。
UDP是无连接的数据传输协议,端与端之间不需要建立连接,且没有类似TCP的那些机制,会发生丢包、乱序等情况。
TCP是数据流模式,而UDP是数据报模式。
7、请画出 TCP 的头部。

1、new 和 malloc 的区别?
- new是运算符,malloc()是一个库函数;
- new会调用构造函数,malloc不会;
- new返回指定类型指针,malloc返回
void*指针; - new会自动计算需分配的空间,malloc不行;
- new可以被重载,malloc不能。
2、指针和引用的区别?
- 指针是一个实体,而引用仅是个别名;
- 引用使用时无需解引用(*),指针需要解引用;
- 引用只能在定义时被初始化一次,之后不可变,而指针可变;
- 引用没有const,指针有const;
- 引用不能为空,指针可以为空;
- 从内存分配上看,指针变量需分配内存,引用则不需要;
- sizeof(引用)得到所指对象的大小,sizeof(指针)得到指针本身的大小;
- 指针和引用的自增(++)运算意义不一样。
3、为什么 TCP 叫数据流模式? UDP 叫数据报模式?
所谓的“流模式”,是指TCP发送端发送几次数据和接收端接收几次数据是没有必然联系的,比如你通过 TCP 连接给另一端发送数据,你只调用了一次 write,发送了100个字节,但是对方可以分10次收完,每次10个字节;你也可以调用10次 write,每次10个字节,但是对方可以一次就收完。
- 原因:这是因为TCP是面向连接的,一个 socket 中收到的数据都是由同一台主机发出,且有序地到达,所以每次读取多少数据都可以。
所谓的“数据报模式”,是指UDP发送端调用了几次 write,接收端必须用相同次数的 read 读完。UDP 是基于报文的,在接收的时候,每次最多只能读取一个报文,报文和报文是不会合并的,如果缓冲区小于报文长度,则多出的部分会被丢弃。
- 原因:这是因为UDP是无连接的,只要知道接收端的 IP 和端口,任何主机都可以向接收端发送数据。 这时候, 如果一次能读取超过一个报文的数据, 则会乱套。
4、简述一下 TCP 的滑动窗口机制
【答】TCP是通过滑动窗口来进行流量控制。
我们知道,在TCP头部里有一个字段叫 Advertised-Window(即窗口大小)。这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据,于是发送端就可以根据这个剩余空间来发送数据,而不会导致接收端处理不过来。
下面是发送端的滑动窗口示意图:

接收端在给发送端回ACK中会汇报自己的 Advertised-Window 剩余缓冲区大小,而发送方会根据这个窗口来控制下一次发送数据的大小。下面是滑动后的示意图(收到36的ack,并发出了46-51的字节):

- Zero Window: 如果接收端处理缓慢,导致发送方的滑动窗口变为0了,怎么办?—— 这时发送端就不发数据了,但发送端会发ZWP(即Zero Window Probe技术)的包给接收方,让接收方回ack更新Window尺寸,一般这个值会设置成3次,每次大约30-60秒。如果3次过后还是0的话,有的TCP实现就会发RST把连接断了。
Silly Window Syndrome:即“糊涂窗口综合症”,当发送端产生数据很慢、或接收端处理数据很慢,导致每次只发送几个字节,也就是我们常说的小数据包 —— 当大量的小数据包在网络中传输,会大大降低网络容量利用率。比如一个20字节的TCP首部+20字节的IP首部+1个字节的数据组成的TCP数据报,有效传输通道利用率只有将近1/40。
- 为了避免发送大量的小数据包,TCP提供了Nagle算法,Nagle算法默认是打开的,可以在Socket设置TCP_NODELAY选项来关闭这个算法。
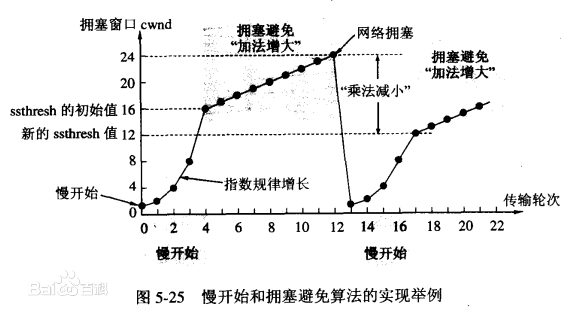
5、TCP的拥塞控制机制是什么?请简单说说。
发送方会维持一个拥塞窗口,刚开始的拥塞窗口和发送窗口相等,一般开始均设置1,然后我们每收到一个确认,就让拥塞窗口大小变为原来的两倍,接着发送分组也是原来的两倍,以此类推,当窗口值等于16(慢开始门限ssthresh初始值),然后我们开始采用“加法增大”的策略,即不在以2倍的方式增加,而是转变为每次加1的方式.直到网络拥塞。我们开始采用“拥塞避免”算法:让新的慢开始门限值变为发生拥塞时候的值的一半,将拥塞窗口置为1,然后让它再次重复,这时一瞬间会将网络中的数据量大量降低。
当cwnd<ssthresh时,使用慢开始算法。
当cwnd>ssthresh时,改用拥塞避免算法。
当接收方cwnd=ssthresh时,慢开始与拥塞避免算法任意。(既可使用慢开始算法,也可使用拥塞避免算法)
拥塞避免算法让拥塞窗口缓慢增长,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口按线性规律缓慢增长。
无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为无法判定,所以都当做拥塞来处理),就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为1,执行慢开始算法。
我们知道TCP通过一个定时器(timer)采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,然而重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这就导致了恶性循环,最终形成“网络风暴” —— TCP的拥塞控制机制就是用于应对这种情况。
首先需要了解一个概念,为了在发送端调节所要发送的数据量,定义了一个“拥塞窗口”(Congestion Window),在发送数据时,将拥塞窗口的大小与接收端ack的窗口大小做比较,取较小者作为发送数据量的上限。
拥塞控制主要是四个算法:
慢启动:意思是刚刚加入网络的连接,一点一点地提速,不要一上来就把路占满。
- 连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
- 每当收到一个ACK,cwnd++; 呈线性上升
- 每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
- 阈值ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”
拥塞避免:当拥塞窗口 cwnd 达到一个阈值时,窗口大小不再呈指数上升,而是以线性上升,避免增长过快导致网络拥塞。
- 每当收到一个ACK,cwnd = cwnd + 1/cwnd
- 每当过了一个RTT,cwnd = cwnd + 1
拥塞发生:当发生丢包进行数据包重传时,表示网络已经拥塞。分两种情况进行处理:
等到RTO超时,重传数据包
- sshthresh = cwnd /2
- cwnd 重置为 1
- 进入慢启动过程
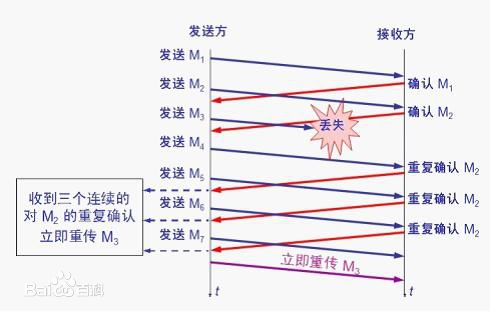
在收到3个duplicate ACK时就开启重传,而不用等到RTO超时
- sshthresh = cwnd = cwnd /2
- 进入快速恢复算法——Fast Recovery
快速恢复:至少收到了3个Duplicated Acks,说明网络也不那么糟糕,可以快速恢复。
- cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
- 重传Duplicated ACKs指定的数据包
- 如果再收到 duplicated Acks,那么cwnd = cwnd +1
- 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了。
6、为什么析构函数要设为虚函数?
【答】在多态中,当使用基类指针或引用操作派生类对象时,如果不把析构函数定义为 visual 函数,则 delete 销毁对象时,只会调用基类的析构函数,不会调用实际派生类对象的析构函数,这样可能造成内存泄露。
7、linux下你常用的命令有哪些?
【答】ll、pwd、touch、rm、mkdir、rmdir、mv、cp、ln
cat、less、more、tail、vim、vimdiff、grep
tar、rz、sz
df、du、free、top、ethtool、sar、netstat、iostat、ps
ifconfig、ping、talnet……
1、static关键字的作用?
在C语言中:
- 加了 static 的全局变量和函数,对其他源文件隐藏(不能跨文件了)。
- static修饰的函数内的局部变量,生存期为整个源程序运行期间,但作用域仍为函数内。
- static变量和全部变量一样,存在静态存储区,会默认初始化为0.
在C++语言中,仍然有上面的作业,但多了下面两个:
- 声明静态成员变量,需要在类体外使用作用域运算符进行初始化。
- 声明静态成员函数,在函数中不能访问非静态成员变量和函数。
2、C++的内存分区?
【答】C++的内存分区共有五个:
- 栈区(stack):主要存放函数参数以及局部变量,由系统自动分配释放。
- 堆区(heap):由用户通过 malloc/new 手动申请,手动释放。
- 全局/静态区:存放全局变量、静态变量;程序结束后由系统释放。
- 字符串常量区:字符串常量就放在这里,程序结束后由系统释放。
- 代码区:存放程序的二进制代码。
3、C++对象的内存布局。
【答】影响对象大小的有如下因素:
- ① 成员变量
- ② 虚函数(产生虚函数表)
- ③ 单一继承(只继承于一个类)
- ④ 多重继承(继承多个类)
- ⑤ 重复继承(继承的多个父类中其父类有相同的超类)
- ⑥ 虚拟继承(使用virtual方式继承,为了保证继承后父类的内存布局只会存在一份)
当然,还会有编译器的影响(比如优化),还有字节对齐的影响。
在单继承的情况下,内存布局:
- 虚函数表在最前面(被重写的虚函数在虚函数表中得到更新)
- 成员变量根据其继承和声明的顺序依次放在后面

在多重继承的情况下,内存布局:
- 每个父类都有自己的虚表。(子类自己的虚函数被放在第一个父类的虚表后)
- 内存布局中,其父类布局依次按照声明顺序排列。

在虚继承的情况下,内存布局:
- 无论是单虚继承还是多虚继承,需要有一个虚基类表来记录虚继承关系,所以此时子类需要多一个 虚基类表指针 ;而且只需要一个即可。

4、vector、map/multimap、unordered_map/unordered_multimap的底层数据结构,以及几种map容器如何选择?
【答】底层数据结构:vector基于数组,map/multimap基于红黑树,unordered_map/unordered_multimap基于哈希表。
根据应用场景进行选择:
- map/unordered_map 不允许重复元素
- multimap/unordered_multimap允许重复元素
- map/multimap底层基于红黑树,元素自动有序,且插入、删除效率高
- unordered_map/unordered_multimap底层基于哈希表,故元素无序,查找效率高。
5、栈溢出的原因及解决办法。
【答】栈的大小一般默认为1M左右,导致栈溢出的常见原因有两个:
- 函数调用层次过深,每调用一次就压一次栈。
- 局部变量占用空间太大。
解决办法:
- 增加栈内存(例如命令:ulimit -s 32768)
- 使用堆,比如动态申请内存、static修饰。
6、内存泄漏怎么产生的?如何避免?
【答】我们所说的内存泄漏一般是指堆内存的泄漏,也就是程序在运行过程中动态申请的内存空间不再使用后没有及时释放,导致那块内存不能被再次使用。
更广义的内存泄漏还包括未对系统资源的及时释放,比如句柄、socket等没有使用相应的函数释放掉,导致系统资源的浪费。
解决方法:
- 养成良好的编码习惯和规范,记得及时释放掉内存或系统资源。
- 重载new和delete,以链表的形式自动管理分配的内存。
- 使用智能指针。
7、TCP建立连接为什么需要三次?断开连接又为什么需要四次?
【答】“三次握手”的主要目的是为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
例如:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送ack包。
“四次挥手”主要是为了确保数据能够完成传输。
因为TCP连接是全双工的(即数据可在两个方向上同时传递),关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
1、core产生的原因,如何调试定位问题?
【答】原因大致有:
- 内存访问越界
- 非法指针
- 堆栈溢出
调试: 如果产生了core文件:gdb ./test core1517然后进行backtrace(bt命令);如果没有core文件,查看dmesg。
2、死锁产生的四个条件,死锁发生后怎么检测和恢复?
【答】死锁的四个必要条件:
- 互斥条件:一个资源每次只能被一个进程使用。
- 请求与保持条件:一个进程在申请新的资源的同时保持对原有资源的占有。
- 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
死锁发生后:
- 检测死锁:首先为每个进程和每个资源指定一个唯一的号码,然后建立资源分配表和进程等待表。
- 解除死锁:当发现有进程死锁后,可以直接撤消死锁的进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态消除为止。
3、堆和栈的区别?
- 栈由编译器自动分配释放,存放函数参数、局部变量等。而堆由程序员手动分配和释放;
- 栈是向低地址扩展的数据结构,是一块连续的内存的区域。而堆是向高地址扩展的数据结构,是不连续的内存区域;
- 栈的默认大小为1M左右,而堆的大小可以达到几G,仅受限于计算机系统中有效的虚拟内存。
4、简单描述一下TCP三次握手和四次挥手的过程。


5、数据库索引的优缺点?
优点:提高数据检索的性能。
缺点:
- 索引会占据物理存储空间
- 当向表中添加/删除数据时,索引也需动态更新,降低了插入/删除的速度
6、数据库的三范式?
- 1NF:字段不可分(原子性)
- 2NF:有主键,非主键字段依赖主键(唯一性)
- 3NF:非主键字段不能相互依赖(每列都与主键有直接关系,不存在传递依赖)
7、如何在一个不安全的环境中实现安全的数据通信?
要实现数据的安全传输,当然就要对数据进行加密了。
如果使用对称加密算法,加解密使用同一个密钥,除了自己保存外,对方也要知道这个密钥,才能对数据进行解密。如果你把密钥也一起传过去,就存在密码泄漏的可能。所以我们使用非对称算法,过程如下:
- 首先 接收方 生成一对密钥,即私钥和公钥;
- 然后,接收方 将公钥发送给 发送方;
- 发送方用收到的公钥对数据加密,再发送给接收方;
- 接收方收到数据后,使用自己的私钥解密。
由于在非对称算法中,公钥加密的数据必须用对应的私钥才能解密,而私钥又只有接收方自己知道,这样就保证了数据传输的安全性。
1、说几个C++11的新特性。
- auto类型推导
- 范围for循环
- lambda函数
- override 和 final 关键字
- 空指针常量nullptr
- 线程支持、智能指针等
2、C++ STL中vector内存用尽后,为啥每次是两倍增长,而不是3倍或其他倍数?
【解】 1, 2, 4, 8, 16, 32,……可以看到,每次需要申请的空间都无法用到前面释放的空间。所以其实2倍并不是最佳增长倍数,最佳增长倍数大约为黄金分割 1.618。 例如:Java中的ArrayList每次扩容为1.5倍。
3、阻塞IO、非阻塞IO、同步IO、异步IO的区别?
【解】这里讨论的是Linux环境下的network IO。
在Richard Stevens的《UNIX® Network Programming Volume 1, Third Edition: The Sockets Networking》的第6.2节介绍了五种IO Model,并说明了各种IO的特点和区别。
- blocking IO
- non-blocking IO
- IO multiplexing
- signal driven IO(不讨论)
- asynchronous IO
当一个网络IO的 read 操作发生时,它会经历两个阶段:
- 等待数据准备 (Waiting for the data to be ready)
- 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
这些IO Model的区别就是在两个阶段上各有不同的情况:
阻塞IO(blocking IO):线程阻塞以等待数据,然后将数据从内核拷贝到进程,返回结果之后才解除阻塞状态。也就是说两个阶段都被block了。
非阻塞IO(non-blocking IO):当对一个非阻塞socket执行读操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。用户进程需要不断地主动进行read操作,一旦数据准备好了,就会把数据拷贝到用户内存。也就是说,第一阶段并不会阻塞线程,但第二阶段拷贝数据还是会阻塞线程。
IO复用(IO multiplexing):这种IO方式也称为event driven IO. 通过使用select/poll/epoll在单个进程中同时处理多个网络连接的IO。例如,当用户进程调用了select,那么整个进程会被block,通过不断地轮询所负责的所有socket,当某个socket的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。在IO复用模型中,实际上对于每一个socket,一般都设置成为non-blocking,但是,整个用户进程其实是一直被block的,先是被select函数block,再是被socket IO第二阶段block。
同步IO(synchronous IO):POSIX中的同步IO定义是—— A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes。也就是说同步IO在IO操作完成之前会阻塞线程,按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。(non-blocking IO也属于同步IO是因为它在真正拷贝数据时也会阻塞线程)
异步IO(asynchronous IO):POSIX中的异步IO定义是—— An asynchronous I/O operation does not cause the requesting process to be blocked。在linux异步IO中,用户进程发起read操作之后,直接返回,去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。也就是说两个阶段都不会阻塞线程。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
4、分时系统与实时系统的区别?
- 分时系统:系统把CPU时间分成很短的时间片,轮流地分配给多个作业。优点:对多个用户的多个作业都能保证足够快的响应时间,并且有效提高了资源的利用率。
- 实时系统:系统对外部输入的信息,能够在规定的时间内(截止期限)处理完毕并做出反应。优点:能够集中地及时地处理并作出反应,高可靠性,安全性。
5、除了sleep之外,usleep()也是linux系统调用,它号称自己是微秒级的,你相信它真的有这么快吗?为什么?
【解】usleep实际上达不到微秒级,主要是因为linux是分时系统,由于进程调度(上下文切换)和系统时间中断精度的原因。
6、简述一下ping的原理。
【解】格式:ping 192.168.0.5
简单地说,ping就是给目标IP地址发送一个 ICMP 回显请求,并要求对方返回一个 ICMP 回显应答来确定两台网络机器是否连通,时延是多少。

在 ICMP 逐层封装的过程中,需要知道源IP、源MAC地址、目的IP、目的MAC地址,前三者是已知的,只需要获取目的MAC地址即可:
- 若在同一网段,只需要发送ARP广播;
- 若不在同一网段,发送ARP广播给交换机,交换机若没有缓存目的IP对应的MAC地址,它会再转发该ARP广播包。
7、进程调度算法有哪些?Linux使用的什么进程调度方法?
【解】进程调度算法有下面几种:
- 先来先服务
- 短作业优先
- 时间片轮转
- 基于优先级
Linux系统中,进程分为实时和非实时两种:
实时进程(相对于普通进程优先级更高)
- SCHED_FIFO — > 相同优先级时,先来先服务;不同优先级,抢占式调度。进程一旦占用cpu则一直运行,直到有更高优先级任务到达或自己放弃。
- SCHED_RR — > 时间片轮转,抢占式调度。
普通进程
- SCHED_OTHER — > priority(静态优先级)+counter(剩余时间片)之和作为动态优先级,基于动态优先级的时间片轮转。
1、static_cast 和 dynamic_cast 的区别。
【解】这两个都是C++中的RTTI的两个操作符,它们之间的主要区别是:
- cast发生的时间不同,一个是static编译时,一个是runtime运行时;
- static_cast是相当于C的强制类型转换,用起来可能有一点危险,不提供运行时的检查来确保转换的安全性。
- dynamic_cast用于转换指针和和引用,不能用来转换对象 —— 主要用于类层次间的上行转换和下行转换,还可以用于类之间的交叉转换。在类层次间进行上行转换时,dynamic_cast和static_cast的效果是一样的;在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全。在多态类型之间的转换主要使用dynamic_cast,因为类型提供了运行时信息。
2、DNS使用什么协议?
【解】DNS使用TCP和UDP协议,具体是:
- DNS服务器间进行域传输的时候使用 TCP 53;
- 客户端查询DNS服务器时使用 UDP 53,但当DNS查询超过512字节,TC标志出现时,使用TCP发送。
这是因为以太网(Ethernet)数据帧的长度必须在46-1500字节之间,这是由以太网的物理特性决定的。这个数据帧长度被称为链路层的MTU(最大传输单元)—— 实际Internet上的标准MTU值为576字节,也就是说链路层的数据区(不包括链路层的头部和尾部)被限制在576字节,所以这也就是网络层IP数据报的长度限制。
因为IP数据报的首部为20字节,所以IP数据报的数据区长度最大为556字节。而这个556字节就是用来放TCP报文段或UDP数据报的。我们知道UDP数据报的首部8字节,所以UDP数据报的数据区最大长度为548字节。—— 如果UDP数据报的数据区大于这个长度,那么总的IP数据包就会大于MTU,这个时候发送方IP层就需要分片(fragmentation),把数据报分成若干片,使每一片都小于MTU,而接收方IP层则需要进行数据报的重组。由于UDP的特性,当某一片数据传送中丢失时,接收方将无法重组数据报,从而导致丢弃整个UDP数据报。所以通常UDP的最大报文长度就限制为512字节或更小。
3、traceroute命令有什么作用?原理是什么?
【解】traceroute命令用于追踪从本机到指定主机的路由途径。
traceroute程序是利用 ICMP 及 IP 头部的 TTL(存活时间)来实现其功能的。每当数据包经过一个路由器,其存活时间就会减1。当其存活时间是0时,主机便取消数据包,并回复一个「ICMP time exceeded」数据包给发出者。
首先,traceroute发送一个TTL为1的数据包到目的地,当路径上的第一个路由器收到这个数据包时,将它的TTL减1。此时,TTL变为0了,所以该路由器会将此数据包丢掉,并送回一个「ICMP time exceeded」消息,traceroute 收到这个消息后,便知道这个路由器存在于这个路径上。接着traceroute 再送出另一个TTL是2 的数据包,发现第2个路由器…… traceroute 每次将送出的数据包的TTL加1来发现另一个路由器,这个重复的动作一直持续到数据包抵达目的地。
当数据包恰好抵达目的地时,由于traceroute所设置的端口是一个一般应用程序都不会用的号码,所以该主机会回送一个「ICMP port unreachable」的消息,而当traceroute 收到这个端口不可达的ICMP消息时,便知道目的地已经到达了。
4、什么是事务?事务有哪些特性?
【解】事务是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。
- 原子性:要么完全执行,要么完全不执行
- 一致性:事务完成时,所有数据保持一致
- 隔离性:多个事务作修改时,互相隔离
- 持久性:事务所作的修改是永久性的
5、MySQL的引擎 InnoDB 和 MyISAM 的区别。
- InnoDB支持外键,MyISAM不支持;
- InnoDB支持事务处理,MyISAM不支持;
- InnoDB是行锁,MyISAM是表锁;
- MyISAM是默认的存储引擎,强调性能。