http://blog.csdn.net/lvsaixia/article/details/51778487
Lambda架构的背景
大数据处理技术需要解决这种可伸缩性与复杂性。首先要认识到这种分布式的本质,要很好地处理分区与复制,不会导致错误分区引起查询失败,而是要将这些逻辑内化到数据库中。当需要扩展系统时,可以非常方便地增加节点,系统也能够针对新节点进行rebalance。其次是要让数据成为不可变的。原始数据永远都不能被修改,这样即使犯了错误,写了错误数据,原来好的数据并不会受到破坏。
Storm的作者NathanMarz提出的一个实时大数据处理框架(Lambda架构)就满足以上两点。Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lambda架构是其根据多年进行分布式大数据系统的经验总结提炼而成。
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
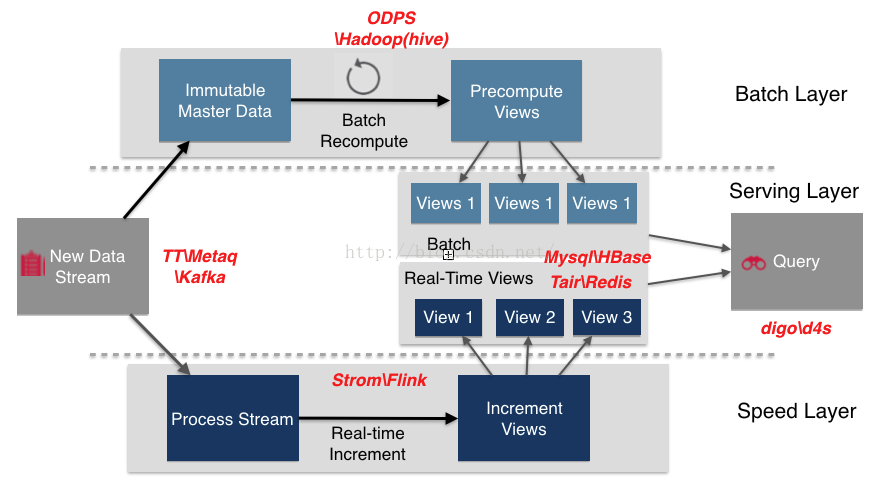
Lambda架构组件选型
下图给出了Lambda架构中各组件在大数据生态系统中和阿里集团的常用组件。数据流存储选用不可变日志的分布式系统Kafa、TT、Metaq;BatchLayer数据集的存储选用Hadoop的HDFS或者阿里云的ODPS;BatchView的加工采用MapReduce;BatchView数据的存储采用MySQL(查询少量的最近结果数据)、hbase(查询大量的历史结果数据)。SpeedLayer采用增量数据处理Storm、Flink;RealtimeView增量结果数据集采用内存数据库Redis。