0x00.About
索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
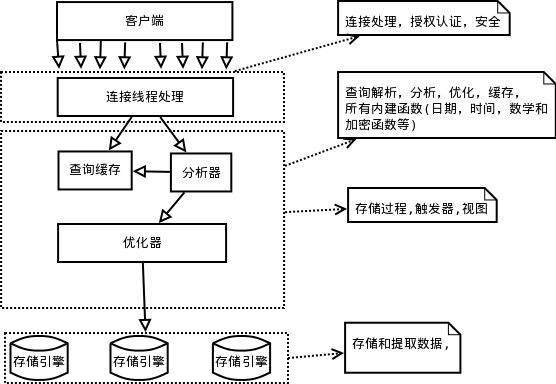
从mysql逻辑架构来看,MySQL有三层架构,第一层连接,第二层查询解析、分析、优化、视图、缓存,第三层,存储引擎。
索引通过分开查询片,节省了扫描查找时间,大大提升查询效率。
大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
索引主要在存储引擎层上,不同的引擎也就有不同的B-Tree算法。
0x01.Hash Index
哈希索引只有Memory, NDB两种引擎支持,Memory引擎默认支持哈希索引,如果多个hash值相同,出现哈希碰撞,那么索引以链表方式存储。
但是,Memory引擎表只对能够适合机器的内存切实有限的数据集。
要使InnoDB或MyISAM支持哈希索引,可以通过伪哈希索引来实现,叫自适应哈希索引。
主要通过增加一个字段,存储hash值,将hash值建立索引,在插入和更新的时候,建立触发器,自动添加计算后的hash到表里。
直接索引
假如有一个非常非常大的表,如下:
CREATE TABLE IF NOT EXISTS
User(idint(10) NOT NULL COMMENT '自增id',namevarchar(128) NOT NULL DEFAULT '' COMMENT '用户名',passvarchar(64) NOT NULL DEFAULT '' COMMENT '用户密码',lasttimestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后登录时间', ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
这个时候,比如说,用户登陆,我需要通过email检索出用户,通过explain得到如下:
mysql> explain SELECT id FROM User WHERE email = ‘ooxx@gmail.com’ LIMIT 1;+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | User | ALL | NULL | NULL | NULL | NULL | 384742 | Using where | +----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
发现rows = 384742也就是要在384742里面进行比对email这个字段的字符串。
这条记录运行的时间是:Query took 0.1744 seconds,数据库的大小是40万。
从上面可以说明,如果直接在email上面建立索引,除了索引区间匹配,还要进行字符串匹配比对,email短还好,如果长的话这个查询代价就比较大。
如果这个时候,在email上建立哈希索引,查询以int查询,性能就比字符串比对查询快多了。
Hash 算法
建立哈希索引,先选定哈希算法,这里选用CRC32。
《高性能MySQL》说到的方法CRC32算法,建立SHA或MD5算法是划算的,本身位数都有可能比email段长了。
INSERT UPDATE SELECT 操作
在表中添加hash值的字段:
mysql> ALTER TABLE User ADD COLUMN email_hash int unsigned NOT NULL DEFAULT 0;
接下来就是在UPDATE和INSERT的时候,自动更新email_hash字段,通过MySQL触发器实现:
DELIMITER | CREATE TRIGGER user_hash_insert BEFORE INSERT ON
UserFOR EACH ROW BEGIN SET NEW.email_hash=crc32(NEW.email); END; | CREATE TRIGGER user_hash_update BEFORE UPDATE ONUserFOR EACH ROW BEGIN SET NEW.email_hash=crc32(NEW.email); END; | DELIMITER ;
这样的话,我们的SELECT请求就会变成这样:
mysql> SELECT email, email_hash FROM User WHERE email_hash = CRC32(“F2dgTSWRBXSZ1d3O@gmail.com”) AND email = “F2dgTSWRBXSZ1d3O@gmail.com”;+----------------------------+------------+ | email | email_hash | +----------------------------+------------+ | F2dgTSWRBXSZ1d3O@gmail.com | 2765311122 | +----------------------------+------------+
在没建立hash索引时候,请求时间是 0.2374 seconds,建立完索引后,请求时间直接变成 0.0003 seconds。
AND email = "F2dgTSWRBXSZ1d3O@gmail.com"是为了防止哈希碰撞导致数据不准确。
0x02.Hash Index 缺点
哈希索引也有几个缺点:
- 索引存放的是hash值,所以仅支持 < = > 以及 IN 操作
- hash索引无法通过操作索引来排序,因为存放的时候经过hash计算,但是计算的hash值和存放的不一定相等,所以无法排序
- 不能避免全表扫描,只是由于在memory表里支持非唯一值hash索引,就是不同的索引键,可能存在相同的hash值
- 如果哈希碰撞很多的话,性能也会变得很差
- 哈希索引无法被用来避免数据的排序操作
MySQL的B-Tree索引和Hash索引的区别
Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以Hash索引的查询效率要远高于B-Tree索引。
可能很多人又有疑问了,既然Hash索引的效率要比B-Tree高很多,为什么大家不都用Hash索引而还要使用B-Tree索引呢?任何事物都是有两面性的,Hash索引也一样,虽然Hash索引效率高,但是Hash索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash索引无法被用来避免数据的排序操作。
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash索引不能利用部分索引键查询。
对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用。
(4)Hash索引在任何时候都不能避免表扫描。
前面已经知道,Hash索引是将索引键通过Hash运算之后,将 Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。