CSS Selector
CSS(即层叠样式表Cascading Stylesheet),Selector来定位(locate)页面上的元素(Elements)。Selenium官网的Document里极力推荐使用CSS locator,而不是XPath来定位元素,原因是CSS locator比XPath locator速度快.
Beautiful Soup
- 支持从HTML或XML文件中提取数据的Python库
- 支持Python标准库中的HTML解析器
- 还支持一些第三方的解析器lxml, 使用的是 Xpath 语法,推荐安装。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了
Beautiful Soup4 安装
官方文档链接:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
可以利用 pip来安装
pip install beautifulsoup4安装解析器(上节课已经安装过)
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml:
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
pip install html5lib
下表列出了主要的解析器:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") | Python的内置标准库;执行速度适中;文档容错能力强 | Python 2.7.3 or 3.2.2前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快;文档容错能力强 ; | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") | 速度快;唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档 | 速度慢;不依赖外部扩展 |
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
- 快速开始
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,'lxml')
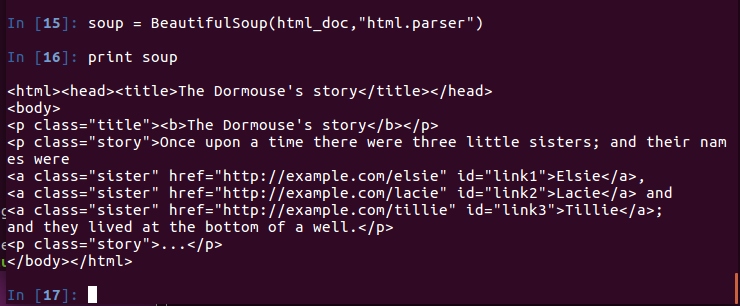
下面我们来打印一下 soup 对象的内容
print soup
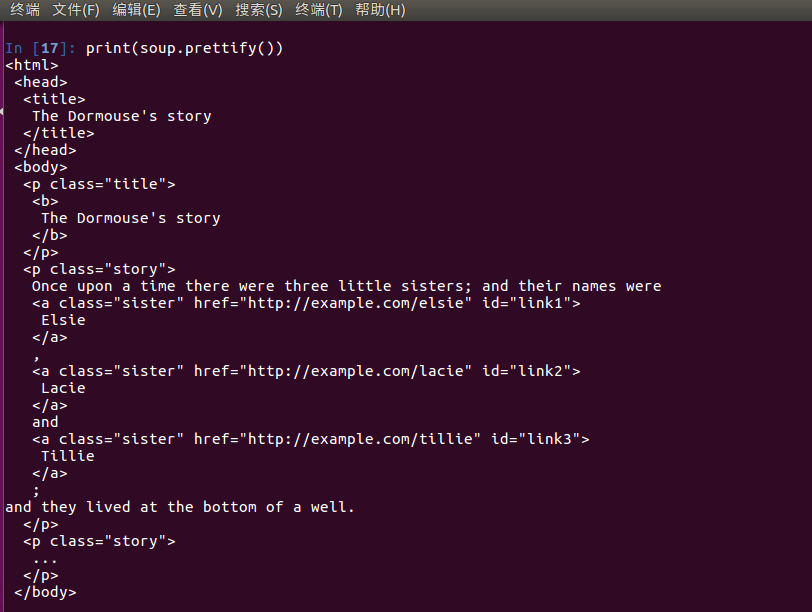
格式化输出soup 对象
print(soup.prettify())
CSS选择器
在写 CSS 时:
标签名不加任何修饰
类名前加点
id名前加 #
利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
通过标签名查找
print soup.select('title') #[<title>The Dormouse's story</title>] print soup.select('a') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] print soup.select('b') #[<b>The Dormouse's story</b>]通过类名查找
print soup.select('.sister') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]通过 id 名查找
print soup.select('#link1') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]直接子标签查找
print soup.select("head > title") #[<title>The Dormouse's story</title>]组合查找
组合查找即标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,
属性和标签不属于同一节点 二者需要用空格分开
print soup.select('p #link1') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]属性查找
查找时还可以加入属性元素,属性需要用中括号括起来
注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到
print soup.select('a[class="sister"]') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] print soup.select('a[href="http://example.com/elsie"]') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]以上的 select 方法返回的结果都是列表形式,可以遍历形式输出
用 get_text() 方法来获取它的内容。
print soup.select('title')[0].get_text() for title in soup.select('title'): print title.get_text()
Tag
Tag 是什么?通俗点讲就是 HTML 中的一个个标签,例如
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print type(soup.select('a')[0])
输出:
bs4.element.Tag
对于 Tag,它有两个重要的属性,是 name 和 attrs,下面我们分别来感受一下
name
print soup.name print soup.select('a')[0].name输出:
[document] 'a'soup 对象本身比较特殊,它的 name 即为 [document],对于其他内部标签,输出的值便为标签本身的名称。
attrs
print soup.select('a')[0].attrs输出:
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}在这里,我们把 soup.select('a')[0] 标签的所有属性打印输出了出来,得到的类型是一个字典。
如果我们想要单独获取某个属性,可以这样,例如我们获取它的 class 叫什么
print soup.select('a')[0].attrs['class']输出:
['sister']
实战案例
我们还是以 腾讯招聘网站
http://hr.tencent.com/position.php?&start=10#a
from bs4 import BeautifulSoup
import urllib2
import urllib
import json
request = urllib2.Request('http://hr.tencent.com/position.php?&start=10#a')
response =urllib2.urlopen(request)
resHtml = response.read()
output =open('tencent.json','w')
html = BeautifulSoup(resHtml,'lxml')
result = html.select('tr[class="even"]')
result2 = html.select('tr[class="odd"]')
result+=result2
print len(result)
for site in result:
item={}
name = site.select('td a')[0].get_text()
detailLink = site.select('td a')[0].attrs['href']
catalog = site.select('td')[1].get_text()
recruitNumber = site.select('td')[2].get_text()
workLocation = site.select('td')[3].get_text()
publishTime = site.select('td')[4].get_text()
item['name']=name
item['detailLink']=detailLink
item['catalog']=catalog
item['recruitNumber']=recruitNumber
item['publishTime']=publishTime
line = json.dumps(item,ensure_ascii=False)
print line
output.write(line.encode('utf-8'))
output.close()
问题?
好,这就是另一种与 XPath 语法有异曲同工之妙的查找方法,觉得哪种更方便?