丁香园防禁封策略-分布式实战
我们以丁香园用药助手项目为例
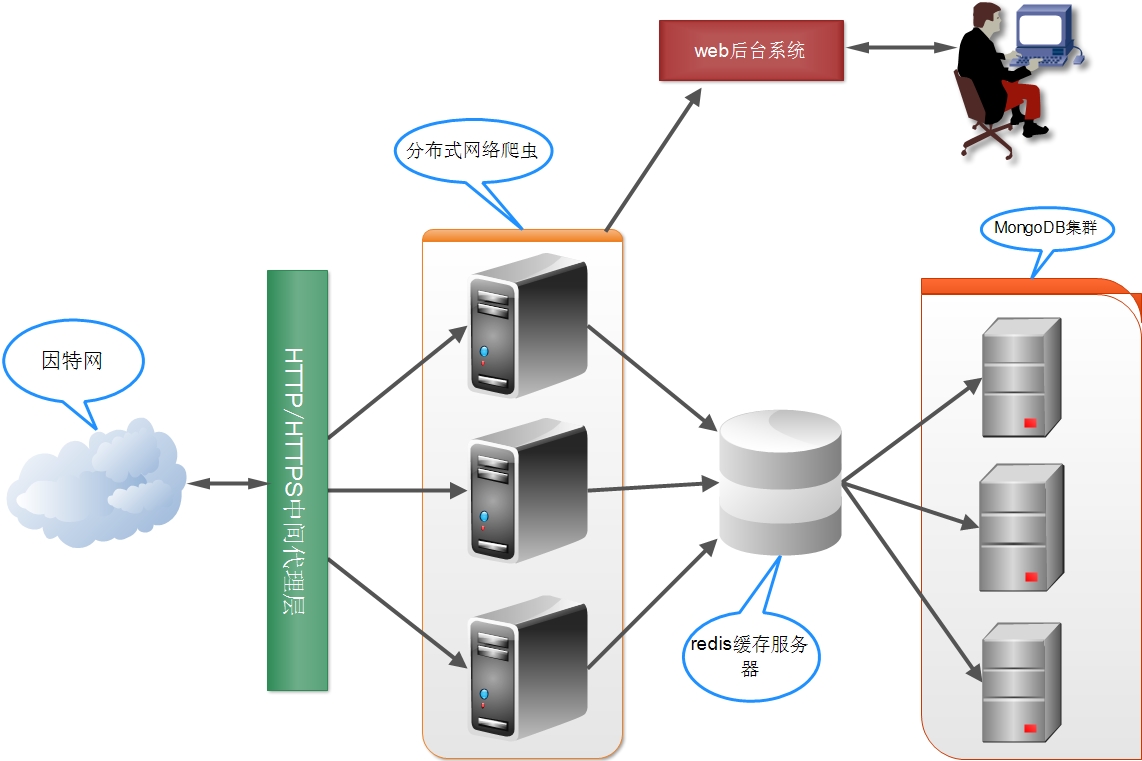
架构示意图如下:
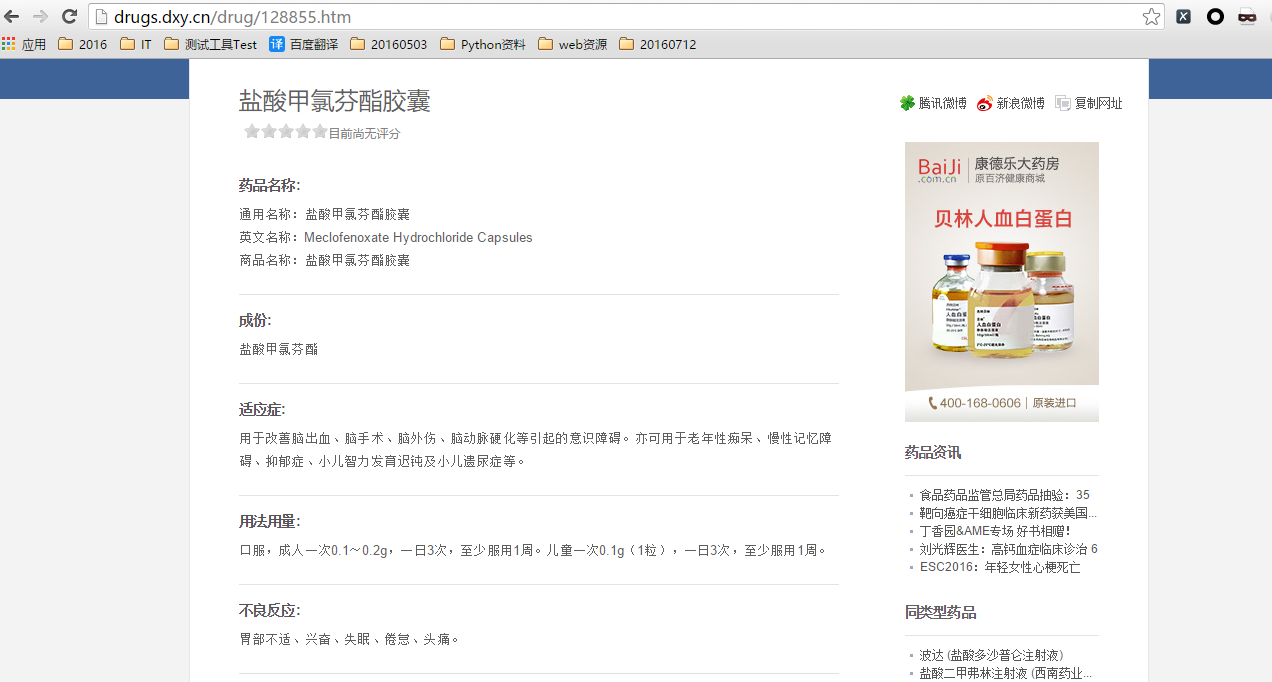
首先通过药理分类采集一遍,按照drug_id排序,发现:
我们要完成 http://drugs.dxy.cn/drug/[50000-150000].htm
正常采集:
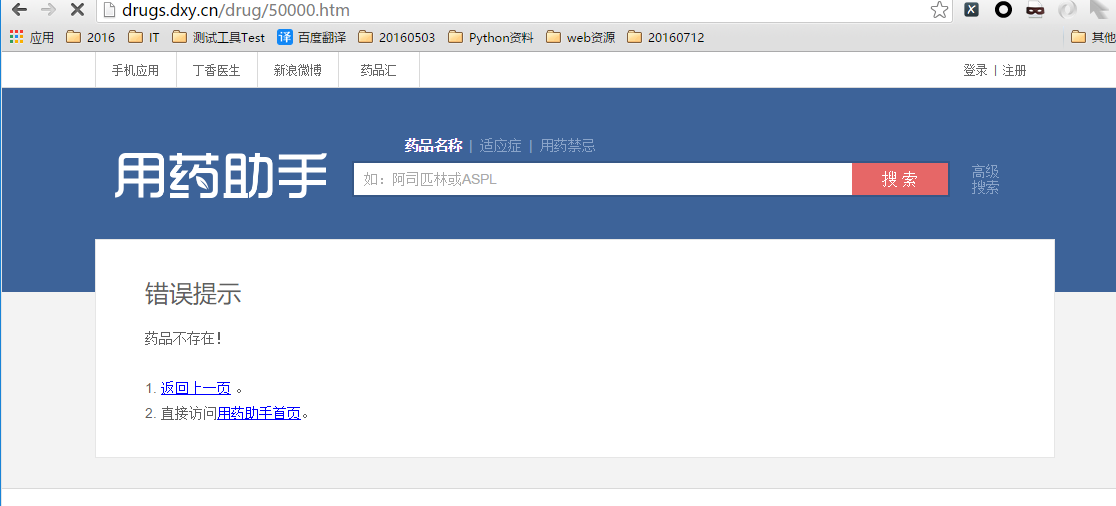
异常数据情况包括如下:
- 药品不存在
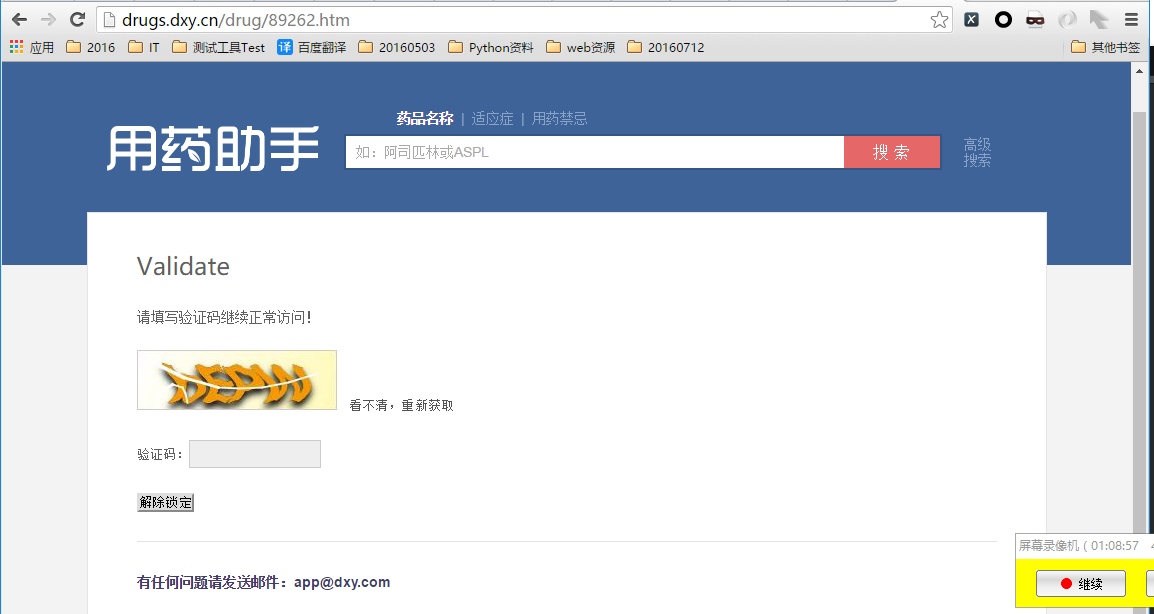
- 当采集频率过快,弹出验证码
- 当天采集累计操作次数过多,弹出禁止
这个时候就需要用到代理
项目流程
1. 创建项目
scrapy startproject drugs_dxy
创建spider
cd drugs_dxy/
scrapy genspider -t basic Drugs dxy.cn
2. items.py下添加类DrugsItem
class DrugsItem(scrapy.Item):
# define the fields for your item here like:
#药品不存在标记
exists = scrapy.Field()
#药品id
drugtId = scrapy.Field()
#数据
data = scrapy.Field()
#标记验证码状态
msg = scrapy.Field()
pass
3. 编辑spider下DrugsSpider类
# -*- coding: utf-8 -*-
import scrapy
from drugs_dxy.items import DrugsItem
import re
class DrugsSpider(scrapy.Spider):
name = "Drugs"
allowed_domains = ["dxy.cn"]
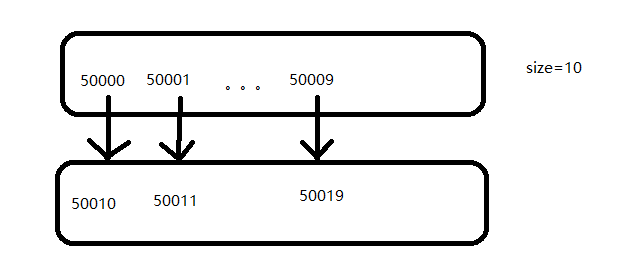
size = 60
def start_requests(self):
for i in xrange(50000,50000+self.size,1):
url ='http://drugs.dxy.cn/drug/%d.htm' % (i)
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
drug_Item = DrugsItem()
drug_Item["drugtId"] = int(re.search('(\d+)',response.url).group(1))
if drug_Item["drugtId"]>=150000:
return
url ='http://drugs.dxy.cn/drug/%d.htm' % (drug_Item["drugtId"]+self.size)
yield scrapy.Request(url=url,callback=self.parse)
if '药品不存在' in response.body:
drug_Item['exists'] = False
yield drug_Item
return
if '请填写验证码继续正常访问' in response.body:
drug_Item["msg"] = u'请填写验证码继续正常访问'
return
drug_Item["data"] = {}
details = response.xpath("//dt")
for detail in details:
detail_name = detail.xpath('./span/text()').extract()[0].split(':')[0]
if detail_name ==u'药品名称':
drug_Item['data'][u'药品名称'] = {}
try:
detail_str = detail.xpath("./following-sibling::*[1]")
detail_value = detail_str.xpath('string(.)').extract()[0].replace('\r','').replace('\t','').strip()
for item in detail_value.split('\n'):
item = item.replace('\r','').replace('\n','').replace('\t','').strip()
name = item.split(u':')[0]
value = item.split(u':')[1]
#print name,value
drug_Item['data'][u'药品名称'][name] = value
except:
pass
else:
detail_str = detail.xpath("./following-sibling::*[1]")
detail_value = detail_str.xpath('string(.)').extract()[0].replace('\r','').replace('\t','').strip()
#print detail_str,detail_value
drug_Item['data'][detail_name] = detail_value
yield drug_Item
4. Scrapy代理设置
4.1 在settings.py文件里
1)启用scrapy_redis组件
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# Specify the host and port to use when connecting to Redis (optional).
REDIS_HOST = '101.200.170.171'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#REDIS_URL = 'redis://user:pass@hostname:9001'
REDIS_PARAMS['password'] = 'itcast.cn'
2) 启用DownLoader中间件;httpproxy
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'drugs_dxy.middlewares.ProxyMiddleware': 400,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
}
3) 设置禁止跳转(code=301、302),超时时间90s
DOWNLOAD_TIMEOUT = 90
REDIRECT_ENABLED = False
4.2 在drugs_dxy目录下创建middlewares.py并编辑(settings.py同级目录)
# -*- coding: utf-8 -*-
import random
import base64
import Queue
import redis
class ProxyMiddleware(object):
def __init__(self, settings):
self.queue = 'Proxy:queue'
# 初始化代理列表
self.r = redis.Redis(host=settings.get('REDIS_HOST'),port=settings.get('REDIS_PORT'),db=1,password=settings.get('REDIS_PARAMS')['password'])
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def process_request(self, request, spider):
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
if proxy['user_pass'] is not None:
#request.meta['proxy'] = "http://YOUR_PROXY_IP:PORT"
request.meta['proxy'] = "http://%s" % proxy['ip_port']
#proxy_user_pass = "USERNAME:PASSWORD"
encoded_user_pass = base64.encodestring(proxy['user_pass'])
request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass
print "********ProxyMiddleware have pass*****" + proxy['ip_port']
else:
#ProxyMiddleware no pass
print request.url, proxy['ip_port']
request.meta['proxy'] = "http://%s" % proxy['ip_port']
def process_response(self, request, response, spider):
"""
检查response.status, 根据status是否在允许的状态码中决定是否切换到下一个proxy, 或者禁用proxy
"""
print("-------%s %s %s------" % (request.meta["proxy"], response.status, request.url))
# status不是正常的200而且不在spider声明的正常爬取过程中可能出现的
# status列表中, 则认为代理无效, 切换代理
if response.status == 200:
print 'rpush',request.meta["proxy"]
self.r.rpush(self.queue, request.meta["proxy"].replace('http://',''))
return response
def process_exception(self, request, exception, spider):
"""
处理由于使用代理导致的连接异常
"""
proxy={}
source, data = self.r.blpop(self.queue)
proxy['ip_port']=data
proxy['user_pass']=None
request.meta['proxy'] = "http://%s" % proxy['ip_port']
new_request = request.copy()
new_request.dont_filter = True
return new_request
5. 运行