斗鱼App妹子图下载
创建项目'douyu'
scrapy startproject douyu
树形图展示项目
cd douyu/
tree
Sublime打开项目
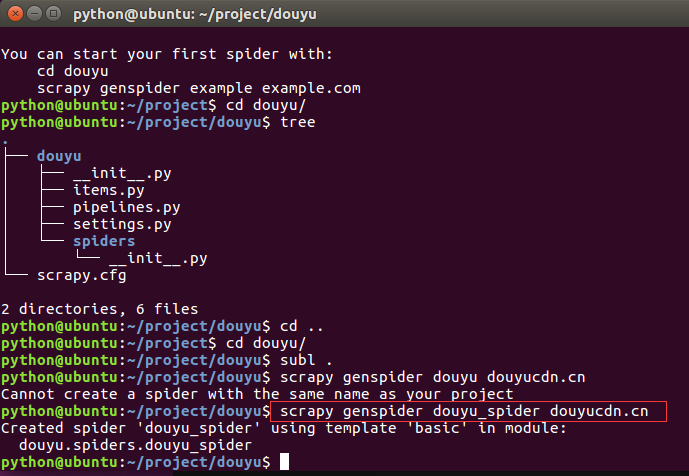
subl .

生成采集模块spider
genspider 在当前项目中创建spider。
语法:
scrapy genspider [-t template] <name> <domain>
$ scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
$ scrapy genspider -d basic
import scrapy
class $classname(scrapy.Spider):
name = "$name"
allowed_domains = ["$domain"]
start_urls = (
'http://www.$domain/',
)
def parse(self, response):
pass
$ scrapy genspider -t basic example example.com
Created spider 'example' using template 'basic' in module:
mybot.spiders.example
创建:
scrapy genspider douyu_spider douyucdn.cn
编辑项目
item.py
import scrapy
class DouyuItem(scrapy.Item):
# define the fields for your item here like:
data = scrapy.Field()
image_path = scrapy.Field()
pass
setting.py
设置 USER_AGENT
USER_AGENT = 'DYZB/2.271 (iPhone; iOS 9.3.2; Scale/3.00)'
douyu_spider.py
# -*- coding: utf-8 -*-
import scrapy
'''添加内容'''
from douyu.items import DouyuItem
import json
class DouyuSpiderSpider(scrapy.Spider):
name = 'douyu_spider'
allowed_domains = ["douyucdn.cn"]
'''添加内容'''
offset = 0
start_urls = (
'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset='+str(offset),
)
def parse(self, response):
'''添加内容'''
data=json.loads(response.body)['data']
if not data:
return
for it in data:
item = DouyuItem()
item['image_url']=it['vertical_src']
item['data']=it
yield item
self.offset+=20
yield scrapy.Request('http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=%s'%str(self.offset),callback=self.parse)
pipeline.py
文件系统存储: 文件以它们URL的 SHA1 hash 作为文件名
sha1sum sha1sum对文件进行唯一较验的hash算法, 用法: sha1sum [OPTION] [FILE]... 参数: -b, --binary 二进制模式读取 -c, --check 根据sha1 num检查文件 -t, --text 文本模式读取(默认)
举例:
f51be4189cce876f3b1bbc1afb38cbd2af62d46b scrapy.cfg
{ 'image_path': 'full/9fdfb243d22ad5e85b51e295fa60e97e6f2159b2.jpg', 'image_url': u'http://staticlive.douyucdn.cn/upload/appCovers/845876/20160816/c4eea823766e2e5e018eee6563e4c420_big.jpg' }
测试:
sudo vi test.txt
拷贝内容
http://staticlive.douyucdn.cn/upload/appCovers/845876/20160816/c4eea823766e2e5e018eee6563e4c420_big.jpg
sha1sum test.txt
9fdfb243d22ad5e85b51e295fa60e97e6f2159b2 test.txt
参考文档:
http://doc.scrapy.org/en/latest/topics/media-pipeline.html
注意: 项目环境 Scrapy 1.0.3 class scrapy.pipelines.images.ImagesPipeline 项目环境 Scrapy 1.0 class scrapy.pipeline.images.ImagesPipeline
下面是你可以在定制的图片管道里重写的方法:
class scrapy.pipelines.images.ImagesPipeline
get_media_requests(item, info)
管道会得到文件的URL并从项目中下载。需要重写 get_media_requests() 方法,并对各个图片URL返回一个Request:
def get_media_requests(self, item, info): for image_url in item['image_urls']: yield scrapy.Request(image_url)当它们完成下载后,结果将以2-元素的元组列表形式传送到
item_completed()方法 results 参数: 每个元组包含(success, file_info_or_error):success是一个布尔值,当图片成功下载时为True,因为某个原因下载失败为Falsefile_info_or_error是一个包含下列关键字的字典(如果成功为 True)或者出问题时为Twisted Failure- url - 文件下载的url。这是从 get_media_requests() 方法返回请求的url。
- path - 图片存储的路径
- checksum - 图片内容的
MD5 hash
下面是
item_completed(results, items, info)中 results 参数的一个典型值:[(True, {'checksum': '2b00042f7481c7b056c4b410d28f33cf', 'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg', 'url': 'http://staticlive.douyucdn.cn/upload/appCovers/420134/20160807/f18f869128d038407742a7c533070daf_big.jpg'}), (False, Failure(...))]默认 get_media_requests() 方法返回 None ,这意味着项目中没有文件可下载。
item_completed(results, items, info)
当图片请求完成时(要么完成下载,要么因为某种原因下载失败),该方法将被调用
item_completed() 方法需要返回一个输出,其将被送到随后的项目管道阶段,因此你需要返回(或者丢弃)项目
举例:
其中我们将下载的图片路径(传入到results中)存储到file_paths 项目组中,如果其中没有图片,我们将丢弃项目:
from scrapy.exceptions import DropItem def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] ''' image_paths=s[] for ok, x in results: if ok: image_paths.append(x['path']) return image_paths ''' if not image_paths : raise DropItem("Item contains no images") item['image_paths'] = image_paths return item默认情况下,item_completed()方法返回项目
定制图片管道:
下面是项目图片管道
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class ImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
image_url = item['image_url']
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_path'] = image_paths[0]
return item
启用pipelines
设置图片下载位置
IMAGES_STORE = '/home/python/project/douyu/photos'
启用PIPELINES:设置item后处理模块
ITEM_PIPELINES = {
'douyu.pipelines.ImagesPipeline': 300,
}
运行爬虫
scrapy runspider douyu/spiders/douyu_spider.py
或者是 scrapy crawl douyu_spider
项目还缺什么
item存储
pipeline.py编写
import json
import codecs
class JsonWriterPipeline(object):
def __init__(self):
self.file = codecs.open('items.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
启用JsonWriterPipeline编写
ITEM_PIPELINES = {
'douyu.pipelines.ImagesPipeline': 300,
'douyu.pipelines.JsonWriterPipeline': 800,
}
再次运行
scrapy crawl douyu_spider