Requests基本用法与药品监督管理局
Requests
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用
urllib2
urllib2是python自带的模块
自定义 'Connection': 'keep-alive',通知服务器交互结束后,不断开连接,即所谓长连接。 当然这也是urllib2不支持keep-alive的解决办法之一,另一个方法是Requests。
安装 Requests
优点:
Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
缺陷:
requests不是python自带的库,需要另外安装 easy_install or pip install
直接使用不能异步调用,速度慢(自动确定响应内容的编码)
pip install requests
文档:
http://cn.python-requests.org/zh_CN/latest/index.html
http://www.python-requests.org/en/master/#
使用方法:
requests.get(url, data={'key1': 'value1'},headers={'User-agent','Mozilla/5.0'})
requests.post(url, data={'key1': 'value1'},headers={'content-type': 'application/json'})
以 药品监督管理局 为例
采集分类 国产药品商品名(6994) 下的所有的商品信息
源码
# -*- coding: utf-8 -*-
import urllib
from lxml import etree
import re
import json
import chardet
import requests
curstart = 2
values = {
'tableId': '32',
'State': '1',
'bcId': '124356639813072873644420336632',
'State': '1',
'tableName': 'TABLE32',
'State': '1',
'viewtitleName': 'COLUMN302',
'State': '1',
'viewsubTitleName': 'COLUMN299,COLUMN303',
'State': '1',
'curstart': str(curstart),
'State': '1',
'tableView': urllib.quote("国产药品商品名"),
'State': '1',
}
post_headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
url = "http://app1.sfda.gov.cn/datasearch/face3/search.jsp"
response = requests.post(url, data=values, headers=post_headers)
resHtml = response.text
print response.status_code
# print resHtml
Urls = re.findall(r'callbackC,\'(.*?)\',null', resHtml)
for url in Urls:
# 坑
print url.encode('gb2312')
查看运行结果,感受一下。
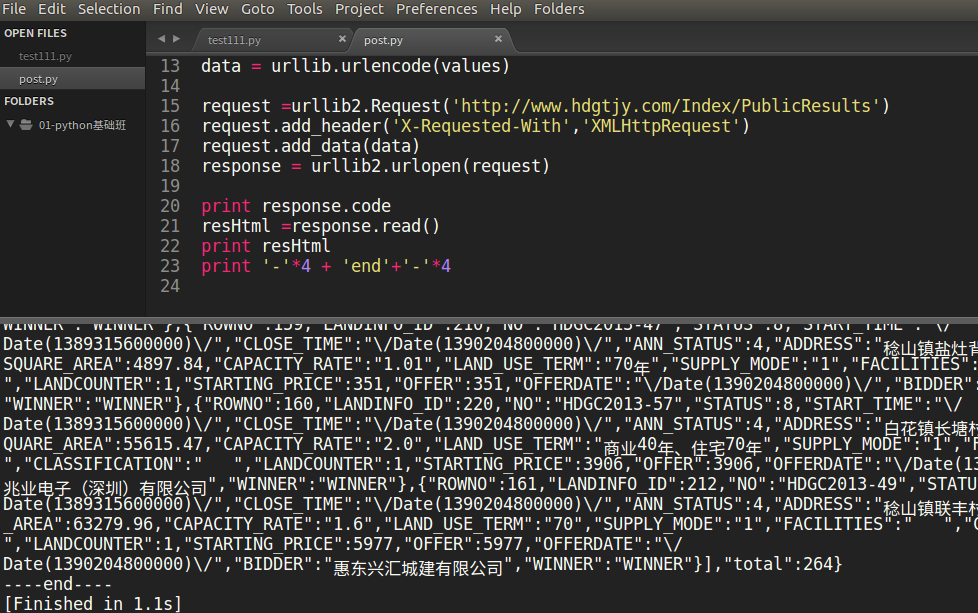
总结
- User-Agent伪装Chrome,欺骗web服务器
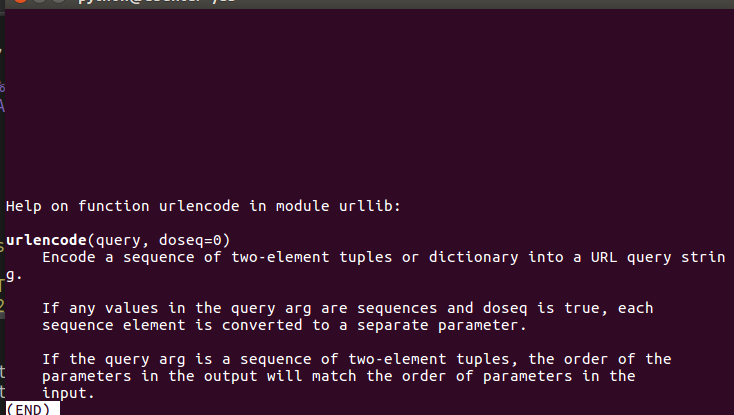
- urlencode 字典类型Dict、元祖 转化成 url query 字符串
练习
- 完成商品详情页采集
- 完成整个项目的采集
详情页
# -*- coding: utf-8 -*-
from lxml import etree
import re
import json
import requests
url ='http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=211315'
get_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'Connection': 'keep-alive',
}
item = {}
response = requests.get(url,headers=get_headers)
resHtml = response.text
print response.encoding
html = etree.HTML(resHtml)
for site in html.xpath('//tr')[1:]:
if len(site.xpath('./td'))!=2:
continue
name = site.xpath('./td')[0].text
if not name:
continue
# value =site.xpath('./td')[1].text
value = re.sub('<.*?>', '', etree.tostring(site.xpath('./td')[1],encoding='utf-8'))
item[name.encode('utf-8')] = value
json.dump(item,open('sfda.json','w'),ensure_ascii=False)
完整项目
# -*- coding: utf-8 -*-
import urllib
from lxml import etree
import re
import json
import requests
def ParseDetail(url):
# url = 'http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=211315'
get_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'Connection': 'keep-alive',
}
item = {}
response = requests.get(url, headers=get_headers)
resHtml = response.text
print response.encoding
html = etree.HTML(resHtml)
for site in html.xpath('//tr')[1:]:
if len(site.xpath('./td')) != 2:
continue
name = site.xpath('./td')[0].text
if not name:
continue
# value =site.xpath('./td')[1].text
value = re.sub('<.*?>', '', etree.tostring(site.xpath('./td')[1], encoding='utf-8'))
value = re.sub('', '', value)
item[name.encode('utf-8').strip()] = value.strip()
# json.dump(item, open('sfda.json', 'a'), ensure_ascii=False)
fp = open('sfda.json', 'a')
str = json.dumps(item, ensure_ascii=False)
fp.write(str + '\n')
fp.close()
def main():
curstart = 2
values = {
'tableId': '32',
'State': '1',
'bcId': '124356639813072873644420336632',
'State': '1',
'tableName': 'TABLE32',
'State': '1',
'viewtitleName': 'COLUMN302',
'State': '1',
'viewsubTitleName': 'COLUMN299,COLUMN303',
'State': '1',
'curstart': str(curstart),
'State': '1',
'tableView': urllib.quote("国产药品商品名"),
'State': '1',
}
post_headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
url = "http://app1.sfda.gov.cn/datasearch/face3/search.jsp"
response = requests.post(url, data=values, headers=post_headers)
resHtml = response.text
print response.status_code
# print resHtml
Urls = re.findall(r'callbackC,\'(.*?)\',null', resHtml)
for url in Urls:
# 坑
url = re.sub('tableView=.*?&', 'tableView=' + urllib.quote("国产药品商品名") + "&", url)
ParseDetail('http://app1.sfda.gov.cn/datasearch/face3/' + url.encode('gb2312'))
if __name__ == '__main__':
main()