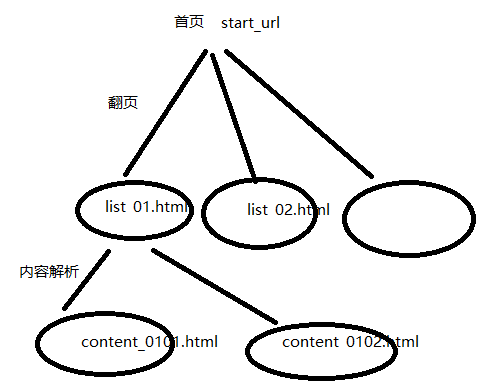
爬虫搜索策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。
1、 深度优先搜索策略(顺藤摸瓜)(Depth-First Search)
即图的深度优先遍历算法。网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
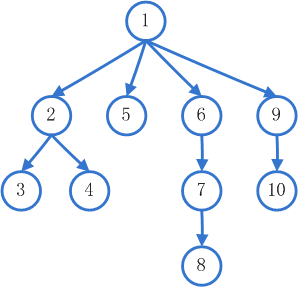
2、 广度(宽度)优先搜索策略(Breadth First Search)
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。
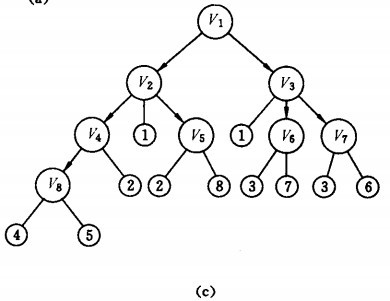
广度优先搜索和深度优先搜索
深度优先搜索算法涉及的是堆栈
广度优先搜索涉及的是队列。
堆栈(stacks)具有后进先出(last in first out,LIFO)的特征
队列(queue)是一种具有先进先出(first in first out,LIFO)特征的线性数据结构
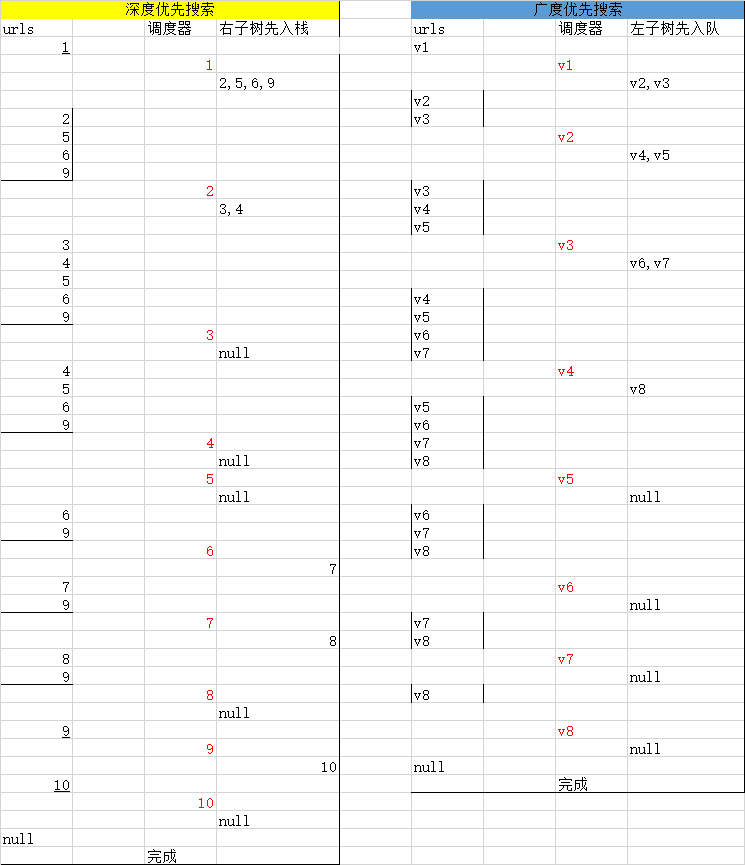
Scrapy是以广度优先还是深度优先进行爬取的呢?
默认情况下,Scrapy使用 LIFO 队列来存储等待的请求。简单的说,就是 深度优先顺序 。深度优先对大多数情况下是更方便的。如果您想以 广度优先顺序 进行爬取,你可以设置以下的设定:
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'