Logging
Scrapy提供了log功能。您可以通过 logging 模块使用。
Log levels
Scrapy提供5层logging级别:
- CRITICAL - 严重错误(critical)
- ERROR - 一般错误(regular errors)
- WARNING - 警告信息(warning messages)
- INFO - 一般信息(informational messages)
- DEBUG - 调试信息(debugging messages)
默认情况下python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG,默认的日志格式为DEBUG级别
如何设置log级别
您可以通过终端选项(command line option) --loglevel/-L 或 LOG_LEVEL 来设置log级别。
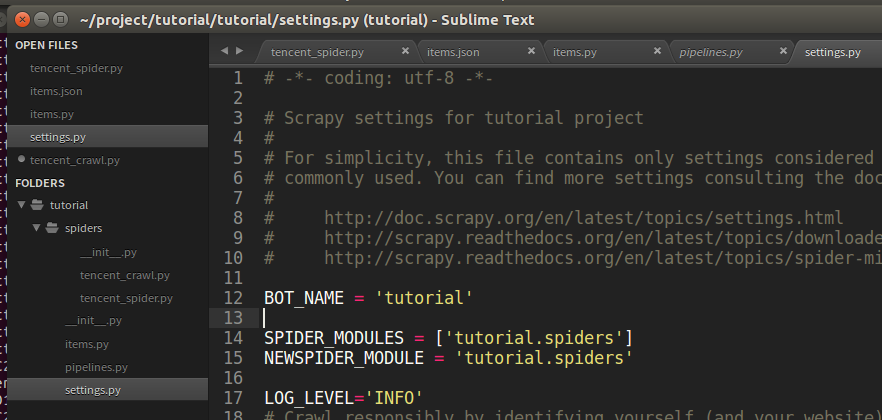
scrapy crawl tencent_crawl -L INFO可以修改配置文件settings.py,添加
LOG_LEVEL='INFO'
在Spider中添加log
Scrapy为每个Spider实例记录器提供了一个logger,可以这样访问:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://scrapinghub.com']
def parse(self, response):
self.logger.info('Parse function called on %s', response.url)
logger是用Spider的名称创建的,但是你可以用你想要的任何自定义logging
例如:
import logging
import scrapy
logger = logging.getLogger('zhangsan')
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://scrapinghub.com']
def parse(self, response):
logger.info('Parse function called on %s', response.url)
Logging设置
以下设置可以被用来配置logging:
LOG_ENABLED
默认: True,启用logging
LOG_ENCODING
默认: 'utf-8',logging使用的编码
LOG_FILE
默认: None,logging输出的文件名
LOG_LEVEL
默认: 'DEBUG',log的最低级别
LOG_STDOUT
默认: False
如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print 'hello' ,其将会在Scrapy log中显示。
案例(一)
tencent_crawl.py添加日志信息如下:
'''
添加日志信息
'''
print 'print',response.url
self.logger.info('info on %s', response.url)
self.logger.warning('WARNING on %s', response.url)
self.logger.debug('info on %s', response.url)
self.logger.error('info on %s', response.url)
完整版如下:
# -*- coding:utf-8 -*-
import scrapy
from tutorial.items import RecruitItem
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class RecruitSpider(CrawlSpider):
name = "tencent_crawl"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position.php?&start=0#a"
]
#提取匹配 'http://hr.tencent.com/position.php?&start=\d+'的链接
page_lx = LinkExtractor(allow=('start=\d+'))
rules = [
#提取匹配,并使用spider的parse方法进行分析;并跟进链接(没有callback意味着follow默认为True)
Rule(page_lx, callback='parseContent',follow=True)
]
def parseContent(self, response):
#print("print settings: %s" % self.settings['LOG_FILE'])
'''
添加日志信息
'''
print 'print',response.url
self.logger.info('info on %s', response.url)
self.logger.warning('WARNING on %s', response.url)
self.logger.debug('info on %s', response.url)
self.logger.error('info on %s', response.url)
for sel in response.xpath('//*[@class="even"]'):
name = sel.xpath('./td[1]/a/text()').extract()[0]
detailLink = sel.xpath('./td[1]/a/@href').extract()[0]
catalog =None
if sel.xpath('./td[2]/text()'):
catalog = sel.xpath('./td[2]/text()').extract()[0]
recruitNumber = sel.xpath('./td[3]/text()').extract()[0]
workLocation = sel.xpath('./td[4]/text()').extract()[0]
publishTime = sel.xpath('./td[5]/text()').extract()[0]
#print name, detailLink, catalog,recruitNumber,workLocation,publishTime
item = RecruitItem()
item['name']=name
item['detailLink']=detailLink
if catalog:
item['catalog']=catalog
item['recruitNumber']=recruitNumber
item['workLocation']=workLocation
item['publishTime']=publishTime
yield item
在settings文件中,修改添加信息
LOG_FILE='ten.log' LOG_LEVEL='INFO'接下来执行:
scrapy crawl tencent_crawl或者command line命令行执行:
scrapy crawl tencent_crawl --logfile 'ten.log' -L INFO
输出如下
print http://hr.tencent.com/position.php?start=10
print http://hr.tencent.com/position.php?start=1340
print http://hr.tencent.com/position.php?start=0
print http://hr.tencent.com/position.php?start=1320
print http://hr.tencent.com/position.php?start=1310
print http://hr.tencent.com/position.php?start=1300
print http://hr.tencent.com/position.php?start=1290
print http://hr.tencent.com/position.php?start=1260
ten.log文件中记录,可以看到级别大于INFO日志输出
2016-08-15 23:10:57 [tencent_crawl] INFO: info on http://hr.tencent.com/position.php?start=70
2016-08-15 23:10:57 [tencent_crawl] WARNING: WARNING on http://hr.tencent.com/position.php?start=70
2016-08-15 23:10:57 [tencent_crawl] ERROR: info on http://hr.tencent.com/position.php?start=70
2016-08-15 23:10:57 [tencent_crawl] INFO: info on http://hr.tencent.com/position.php?start=1320
2016-08-15 23:10:57 [tencent_crawl] WARNING: WARNING on http://hr.tencent.com/position.php?start=1320
2016-08-15 23:10:57 [tencent_crawl] ERROR: info on http://hr.tencent.com/position.php?start=1320
案例(二)
tencent_spider.py添加日志信息如下:
logger = logging.getLogger('zhangsan')
'''
添加日志信息
'''
print 'print',response.url
self.logger.info('info on %s', response.url)
self.logger.warning('WARNING on %s', response.url)
self.logger.debug('info on %s', response.url)
self.logger.error('info on %s', response.url)
完整版如下:
import scrapy
from tutorial.items import RecruitItem
import re
import logging
logger = logging.getLogger('zhangsan')
class RecruitSpider(scrapy.spiders.Spider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position.php?&start=0#a"
]
def parse(self, response):
#logger.info('spider tencent Parse function called on %s', response.url)
'''
添加日志信息
'''
print 'print',response.url
logger.info('info on %s', response.url)
logger.warning('WARNING on %s', response.url)
logger.debug('info on %s', response.url)
logger.error('info on %s', response.url)
for sel in response.xpath('//*[@class="even"]'):
name = sel.xpath('./td[1]/a/text()').extract()[0]
detailLink = sel.xpath('./td[1]/a/@href').extract()[0]
catalog =None
if sel.xpath('./td[2]/text()'):
catalog = sel.xpath('./td[2]/text()').extract()[0]
recruitNumber = sel.xpath('./td[3]/text()').extract()[0]
workLocation = sel.xpath('./td[4]/text()').extract()[0]
publishTime = sel.xpath('./td[5]/text()').extract()[0]
#print name, detailLink, catalog,recruitNumber,workLocation,publishTime
item = RecruitItem()
item['name']=name
item['detailLink']=detailLink
if catalog:
item['catalog']=catalog
item['recruitNumber']=recruitNumber
item['workLocation']=workLocation
item['publishTime']=publishTime
yield item
nextFlag = response.xpath('//*[@id="next"]/@href')[0].extract()
if 'start' in nextFlag:
curpage = re.search('(\d+)',response.url).group(1)
page =int(curpage)+10
url = re.sub('\d+',str(page),response.url)
print url
yield scrapy.Request(url, callback=self.parse)
在settings文件中,修改添加信息
LOG_FILE='tencent.log' LOG_LEVEL='WARNING'接下来执行:
scrapy crawl tencent或者command line命令行执行:
scrapy crawl tencent --logfile 'tencent.log' -L WARNING
输出信息
print http://hr.tencent.com/position.php?&start=0
http://hr.tencent.com/position.php?&start=10
print http://hr.tencent.com/position.php?&start=10
http://hr.tencent.com/position.php?&start=20
print http://hr.tencent.com/position.php?&start=20
http://hr.tencent.com/position.php?&start=30
tencent.log文件中记录,可以看到级别大于INFO日志输出
2016-08-15 23:22:59 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=0
2016-08-15 23:22:59 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=0
2016-08-15 23:22:59 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=10
2016-08-15 23:22:59 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=10
小试 LOG_STDOUT
settings.py
LOG_FILE='tencent.log'
LOG_STDOUT=True
LOG_LEVEL='INFO'
scrapy crawl tencent
输出:
空
tencent.log日志文件
2016-08-15 23:28:32 [stdout] INFO: http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [stdout] INFO: print
2016-08-15 23:28:32 [stdout] INFO: http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [zhangsan] INFO: info on http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [stdout] INFO: http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [stdout] INFO: print
2016-08-15 23:28:33 [stdout] INFO: http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [zhangsan] INFO: info on http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=120
scrapy之Logging使用
#coding:utf-8
######################
##Logging的使用
######################
import logging
'''
1. logging.CRITICAL - for critical errors (highest severity) 致命错误
2. logging.ERROR - for regular errors 一般错误
3. logging.WARNING - for warning messages 警告+错误
4. logging.INFO - for informational messages 消息+警告+错误
5. logging.DEBUG - for debugging messages (lowest severity) 低级别
'''
logging.warning("This is a warning")
logging.log(logging.WARNING,"This is a warning")
#获取实例对象
logger=logging.getLogger()
logger.warning("这是警告消息")
#指定消息发出者
logger = logging.getLogger('SimilarFace')
logger.warning("This is a warning")
#在爬虫中使用log
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://scrapinghub.com']
def parse(self, response):
#方法1 自带的logger
self.logger.info('Parse function called on %s', response.url)
#方法2 自己定义个logger
logger.info('Parse function called on %s', response.url)
'''
Logging 设置
• LOG_FILE
• LOG_ENABLED
• LOG_ENCODING
• LOG_LEVEL
• LOG_FORMAT
• LOG_DATEFORMAT • LOG_STDOUT
命令行中使用
--logfile FILE
Overrides LOG_FILE
--loglevel/-L LEVEL
Overrides LOG_LEVEL
--nolog
Sets LOG_ENABLED to False
'''
import logging
from scrapy.utils.log import configure_logging
configure_logging(install_root_handler=False)
#定义了logging的些属性
logging.basicConfig(
filename='log.txt',
format='%(levelname)s: %(levelname)s: %(message)s',
level=logging.INFO
)
#运行时追加模式
logging.info('进入Log文件')
logger = logging.getLogger('SimilarFace')
logger.warning("也要进入Log文件")